Ankarlådor
Svep för att visa menyn
Anchor box är en fördefinierad avgränsningsruta med fast storlek och bildförhållande, placerad på specifika positioner över en bild.
Varför Anchor Boxes Används vid Objektigenkänning
Anchor boxes är ett grundläggande koncept i moderna objektigenkänningsmodeller såsom Faster R-CNN och YOLO. De fungerar som fördefinierade referensrutor som hjälper till att upptäcka objekt av olika storlekar och bildförhållanden, vilket gör detekteringen snabbare och mer tillförlitlig.
Istället för att upptäcka objekt från grunden använder modeller anchor boxes som utgångspunkt och justerar dem för att bättre passa de upptäckta objekten. Detta tillvägagångssätt förbättrar effektivitet och noggrannhet, särskilt vid detektering av objekt i varierande skala.
Skillnad Mellan Anchor Box och Bounding Box
- Anchor Box: en fördefinierad mall som fungerar som referens vid objektigenkänning;
- Bounding Box: den slutliga förutsagda rutan efter att justeringar har gjorts på en anchor box för att matcha det faktiska objektet.

Till skillnad från avgränsningsrutor, som justeras dynamiskt under prediktionen, är ankarboxar fixerade på specifika positioner innan någon objektdetektering sker. Modeller lär sig att förfina ankarboxar genom att justera deras storlek, position och bildförhållande, vilket slutligen omvandlar dem till slutliga avgränsningsrutor som exakt representerar detekterade objekt.
Hur ett nätverk genererar ankarboxar
Ankarboxar appliceras inte direkt på en bild utan på funktionskartor som extraherats från bilden. Efter funktionsutvinning placeras en uppsättning ankarboxar på dessa funktionskartor, varierande i storlek och bildförhållande. Valet av ankarboxarnas former är avgörande och innebär en avvägning mellan att detektera små och stora objekt.
För att definiera ankarboxarnas storlekar använder modeller vanligtvis en kombination av manuell val och klustringsalgoritmer som K-Means för att analysera datamängden och fastställa de vanligaste objektformerna och storlekarna. Dessa fördefinierade ankarboxar appliceras sedan på olika platser över funktionskartorna. Till exempel kan en objektdetekteringsmodell använda ankarboxar med storlekar (16x16), (32x32), (64x64), med bildförhållanden såsom 1:1, 1:2, and 2:1.
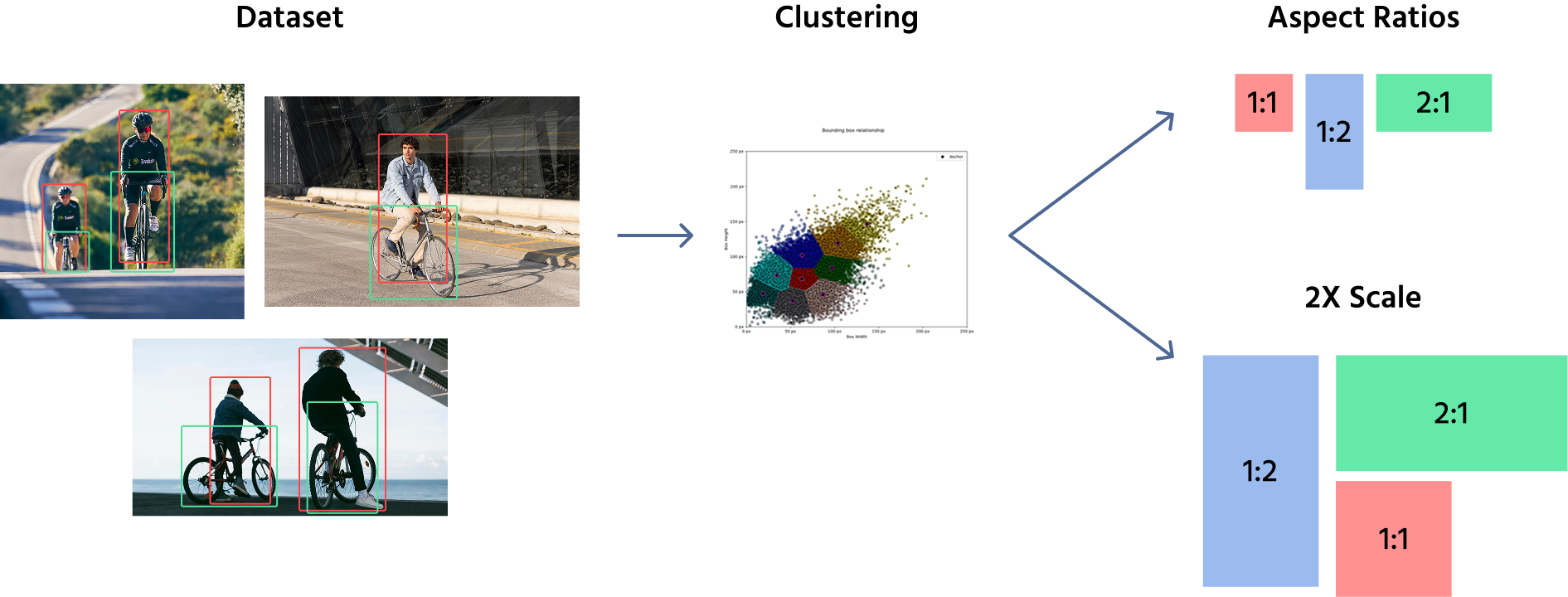
När dessa ankarlådor har definierats tillämpas de på funktionskartor, inte på originalbilden. Modellen tilldelar flera ankarlådor till varje plats på funktionskartan, vilket täcker olika former och storlekar. Under träningen justerar nätverket ankarlådorna genom att förutsäga förskjutningar, vilket förfinar deras storlek och position för att bättre passa objekten.
Från ankarlåda till avgränsningsruta
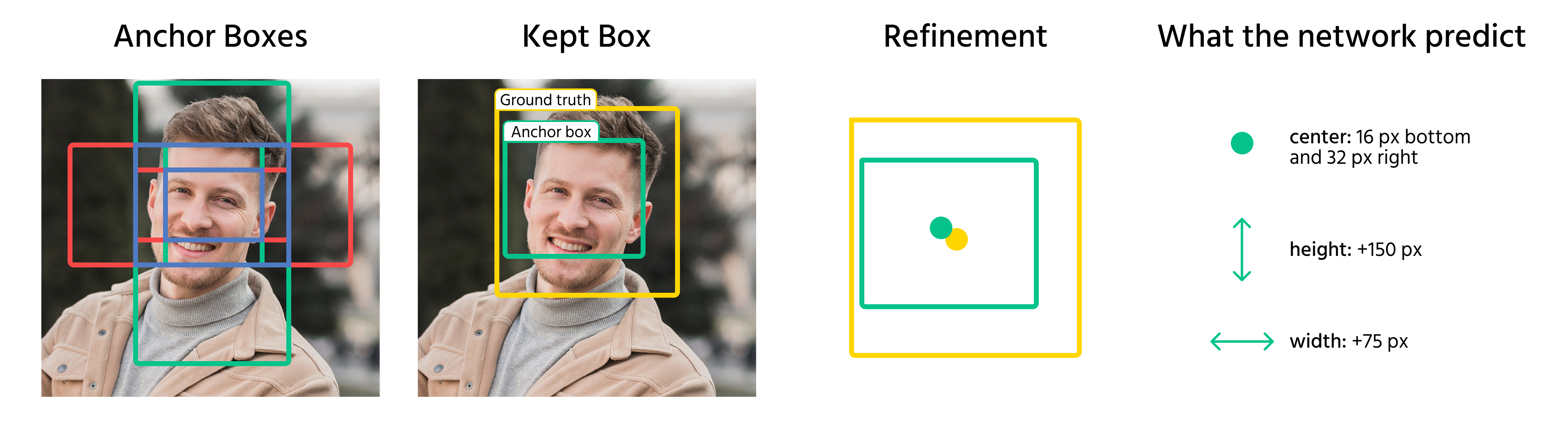
När ankarlådor har tilldelats objekt förutspår modellen förskjutningar för att förfina dem. Dessa förskjutningar inkluderar:
- Justering av lådans mittkoordinater;
- Skalning av bredd och höjd;
- Förskjutning av lådan för att bättre anpassa den till objektet.
Genom att tillämpa dessa transformationer omvandlar modellen ankarlådor till slutliga avgränsningsrutor som noggrant matchar objekten i en bild.
Metoder som inte använder ankare eller minskar deras antal
Även om ankarboxar är allmänt använda, strävar vissa modeller efter att minska beroendet av dem eller eliminera dem helt:
- Ankarfria metoder: Modeller som
CenterNetochFCOSförutspår objektpositioner direkt utan fördefinierade ankare, vilket minskar komplexiteten; - Metoder med reducerat antal ankare:
EfficientDetochYOLOv4optimerar antalet använda ankarboxar för att balansera detekteringshastighet och noggrannhet.
Dessa metoder syftar till att förbättra effektiviteten i objektdetektering samtidigt som hög prestanda bibehålls, särskilt för realtidsapplikationer.
Sammanfattningsvis är ankarboxar en avgörande del av objektdetektering och hjälper modeller att effektivt identifiera objekt i olika storlekar och bildförhållanden. Nya framsteg undersöker dock sätt att minska eller eliminera ankarboxar för ännu snabbare och mer flexibel detektering.
1. Vad är den primära rollen för anchor boxes vid objektigenkänning?
2. Hur skiljer sig anchor boxes från bounding boxes?
3. Vilken metod används vanligtvis för att bestämma optimala storlekar på anchor boxes?
Tack för dina kommentarer!
Fråga AI
Fråga AI

Fråga vad du vill eller prova någon av de föreslagna frågorna för att starta vårt samtal
