Översikt av Yolo-modellen
Svep för att visa menyn
YOLO (You Only Look Once)-algoritmen är en snabb och effektiv modell för objektdetektering. Till skillnad från traditionella metoder som R-CNN, vilka använder flera steg, bearbetar YOLO hela bilden i ett enda genomlopp, vilket gör den idealisk för realtidsapplikationer.
Hur YOLO skiljer sig från R-CNN-metoder
Traditionella metoder för objektdetektering, såsom R-CNN och dess varianter, bygger på en tvåstegsprocess: först genereras regionförslag, därefter klassificeras varje föreslagen region. Även om detta är effektivt, är metoden beräkningsintensiv och saktar ner inferensen, vilket gör den mindre lämplig för realtidsapplikationer.
YOLO (You Only Look Once) använder en radikalt annorlunda metod. Den delar upp inmatningsbilden i ett rutnät och förutspår avgränsningsrutor och klass-sannolikheter för varje cell i ett enda framåtriktat pass. Denna design behandlar objektdetektering som ett enda regressionsproblem, vilket gör att YOLO kan uppnå prestanda i realtid.
Till skillnad från R-CNN-baserade metoder som endast fokuserar på lokala regioner, bearbetar YOLO hela bilden på en gång, vilket gör det möjligt att fånga global kontextuell information. Detta leder till bättre prestanda vid detektering av flera eller överlappande objekt, samtidigt som hög hastighet och noggrannhet bibehålls.
YOLO-arkitektur och rutnätsbaserade prediktioner
YOLO delar upp en inmatningsbild i ett S × S-rutnät, där varje rutnätscell ansvarar för att detektera objekt vars centrum faller inom cellen. Varje cell förutspår koordinater för avgränsningsruta (x, y, bredd, höjd), ett konfidensvärde för objekt och klass-sannolikheter. Eftersom YOLO bearbetar hela bilden i ett enda framåtriktat pass är den mycket effektiv jämfört med tidigare modeller för objektdetektering.
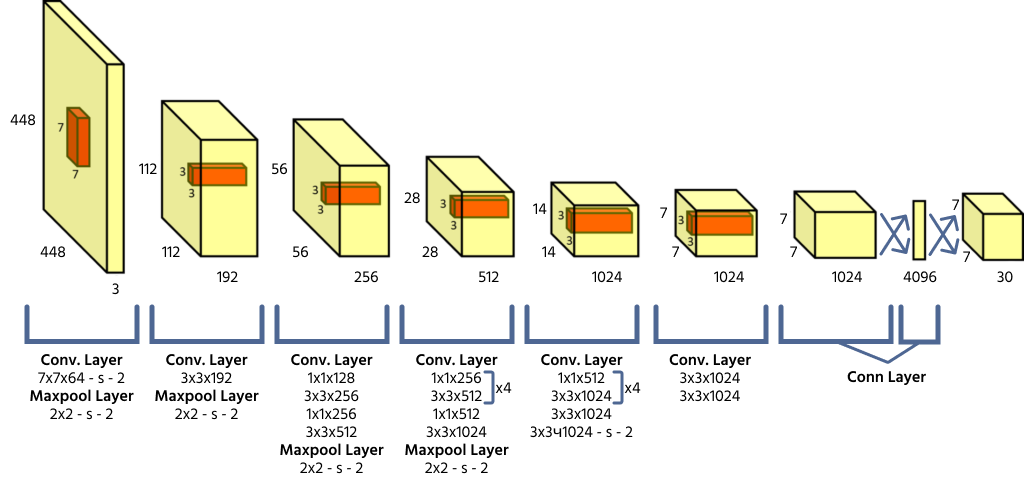
Förlustfunktion och klasskonfidenspoäng
YOLO optimerar detekteringsnoggrannhet med en anpassad förlustfunktion, som inkluderar:
- Lokaliseringsförlust: mäter noggrannheten för avgränsningsrutor;
- Konfidensförlust: säkerställer att förutsägelser korrekt indikerar förekomst av objekt;
- Klassificeringsförlust: utvärderar hur väl den förutsagda klassen matchar den sanna klassen.
För att förbättra resultaten använder YOLO ankarlådor och icke-maximal undertryckning (NMS) för att ta bort överflödiga detekteringar.
Fördelar med YOLO: Avvägning mellan hastighet och noggrannhet
YOLO:s främsta fördel är hastighet. Eftersom detektering sker i ett enda steg är YOLO mycket snabbare än R-CNN-baserade metoder, vilket gör det lämpligt för realtidsapplikationer som autonom körning och övervakning. Tidigare versioner av YOLO hade dock svårigheter med att detektera små objekt, något som förbättrats i senare versioner.
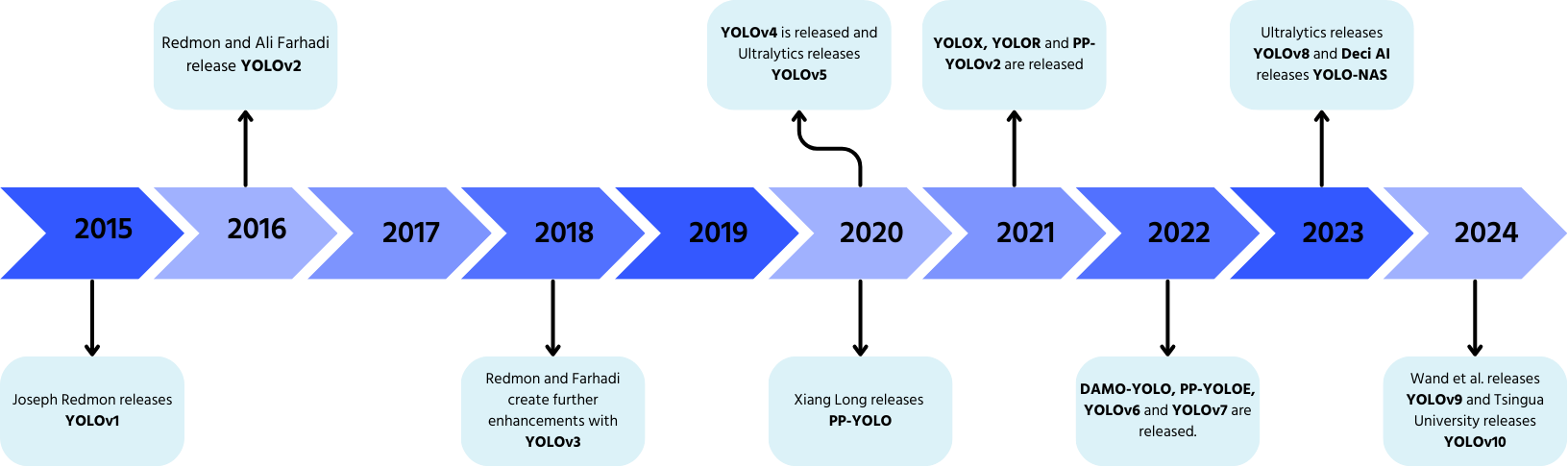
YOLO: En kort historik
YOLO, utvecklat av Joseph Redmon och Ali Farhadi år 2015, förändrade objektigenkänning med sin enkelpassbearbetning.
- YOLOv2 (2016): lade till batchnormalisering, ankarboxar och dimensionskluster;
- YOLOv3 (2018): introducerade en effektivare ryggrad, flera ankarpunkter och spatial pyramidpooling;
- YOLOv4 (2020): lade till Mosaic-dataförstärkning, ett ankarfritt detekteringshuvud och en ny förlustfunktion;
- YOLOv5: förbättrade prestanda med hyperparameteroptimering, experimentspårning och automatiska exportfunktioner;
- YOLOv6 (2022): öppen källkod av Meituan och används i autonoma leveransrobotar;
- YOLOv7: utökade funktionaliteten till att inkludera posestimering;
- YOLOv8 (2023): förbättrade hastighet, flexibilitet och effektivitet för vision AI-uppgifter;
- YOLOv9: introducerade Programmerbar Gradientinformation (PGI) och Generalized Efficient Layer Aggregation Network (GELAN);
- YOLOv10: utvecklad av Tsinghua University, eliminerar Non-Maximum Suppression (NMS) med ett End-to-End detekteringshuvud;
- YOLOv11: den senaste modellen som erbjuder topprestanda inom objektigenkänning, segmentering och klassificering.
Tack för dina kommentarer!
Fråga AI
Fråga AI

Fråga vad du vill eller prova någon av de föreslagna frågorna för att starta vårt samtal
