Förutsägelser av Avgränsningsrutor
Svep för att visa menyn
Avgränsningsrutor är avgörande för objektigenkänning och används för att markera objektens positioner. Objektigenkänningsmodeller använder dessa rutor för att definiera position och dimensioner för identifierade objekt i en bild. Noggrann förutsägelse av avgränsningsrutor är grundläggande för att säkerställa tillförlitlig objektigenkänning.
Hur CNN:er förutsäger koordinater för avgränsningsrutor
Konvolutionella neurala nätverk (CNN:er) bearbetar bilder genom lager av konvolutioner och pooling för att extrahera egenskaper. För objektigenkänning genererar CNN:er feature maps som representerar olika delar av en bild. Förutsägelse av avgränsningsrutor uppnås vanligtvis genom:
- Extrahera egenskapsrepresentationer från bilden;
- Applicera en regressionsfunktion för att förutsäga koordinater för avgränsningsrutor;
- Klassificera de identifierade objekten inom varje ruta.
Förutsägelser för avgränsningsrutor representeras som numeriska värden som motsvarar:
- (x, y): koordinaterna för rutans centrum;
- (w, h): rutans bredd och höjd.
Exempel: Förutsäga avgränsningsrutor med en förtränad modell
Istället för att träna en CNN från grunden kan vi använda en förtränad modell såsom Faster R-CNN från TensorFlows model zoo för att förutsäga avgränsningsrutor på en bild. Nedan visas ett exempel på hur man laddar en förtränad modell, laddar en bild, gör förutsägelser och visualiserar avgränsningsrutorna med klassetiketter.
Importera bibliotek
import cv2
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
from tensorflow.image import draw_bounding_boxes
Ladda modell och bild
# Load a pretrained Faster R-CNN model from TensorFlow Hub
model = hub.load("https://www.kaggle.com/models/tensorflow/faster-rcnn-resnet-v1/TensorFlow2/faster-rcnn-resnet101-v1-1024x1024/1")
# Load and preprocess the image
img_path = "../../../Documents/Codefinity/CV/Pictures/Section 4/object_detection/bikes_n_persons.png"
img = cv2.imread(img_path)
Förbehandla bilden
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = tf.image.resize(img, (1024, 1024))
# Convert to uint8
img_resized = tf.cast(img_resized, dtype=tf.uint8)
# Convert to tensor
img_tensor = tf.convert_to_tensor(img_resized)[tf.newaxis, ...]
Gör en prediktion och extrahera bounding box-egenskaper
# Make predictions
output = model(img_tensor)
# Extract bounding box coordinates
num_detections = int(output['num_detections'][0])
bboxes = output['detection_boxes'][0][:num_detections].numpy()
class_names = output['detection_classes'][0][:num_detections].numpy().astype(int)
scores = output['detection_scores'][0][:num_detections].numpy()
# Example labels from COCO dataset
labels = {1: "Person", 2: "Bike"}
Rita bounding boxes
# Draw bounding boxes with labels
for i in range(num_detections):
# Confidence threshold
if scores[i] > 0.5:
y1, x1, y2, x2 = bboxes[i]
start_point = (int(x1 * img.shape[1]), int(y1 * img.shape[0]))
end_point = (int(x2 * img.shape[1]), int(y2 * img.shape[0]))
cv2.rectangle(img, start_point, end_point, (0, 255, 0), 2)
# Get label or 'Unknown'
label = labels.get(class_names[i], "Unknown")
cv2.putText(img, f"{label} ({scores[i]:.2f})", (start_point[0], start_point[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
Visualisera
# Display image with bounding boxes and labels
plt.figure()
plt.imshow(img)
plt.axis("off")
plt.title("Object Detection with Bounding Boxes and Labels")
plt.show()
Resultat:

Regressionsbaserade förutsägelser av avgränsningsrutor
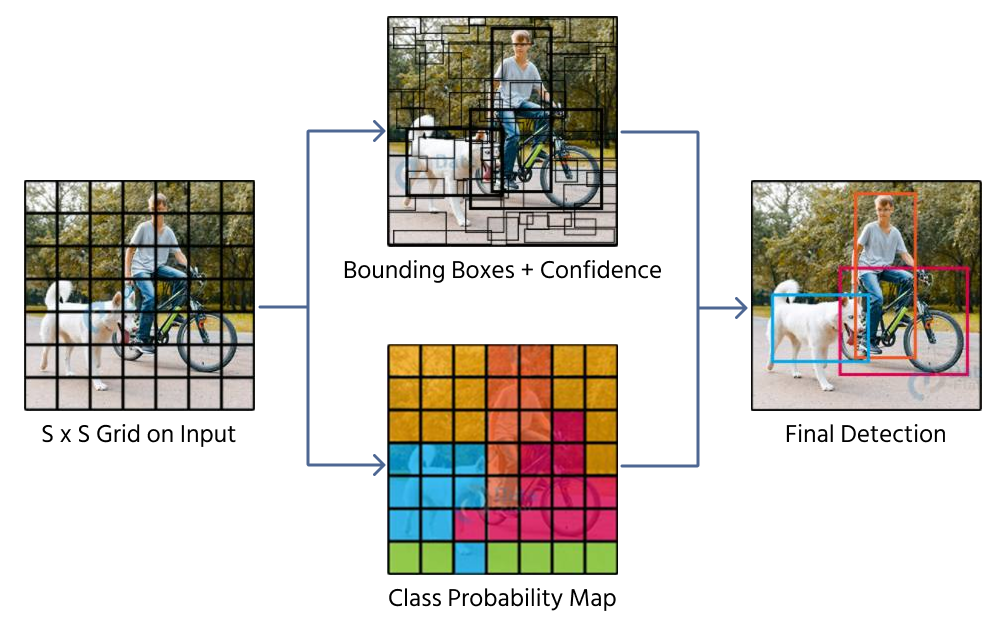
Ett tillvägagångssätt för att förutsäga avgränsningsrutor är direkt regression, där ett CNN returnerar fyra numeriska värden som representerar boxens position och storlek. Modeller som YOLO (You Only Look Once) använder denna teknik genom att dela upp en bild i ett rutnät och tilldela förutsägelser av avgränsningsrutor till rutnätsceller.
Direkt regression har dock begränsningar:
- Svårigheter med objekt av varierande storlek och proportioner;
- Hanterar inte överlappande objekt effektivt;
- Avgränsningsrutor kan förskjutas oförutsägbart, vilket leder till inkonsekvenser.
Ankarbaserade vs. Ankarfria metoder
Ankarbaserade metoder
Ankarboxar är fördefinierade avgränsningsrutor med fasta storlekar och proportioner. Modeller som Faster R-CNN och SSD (Single Shot MultiBox Detector) använder ankarboxar för att förbättra prediktionsnoggrannheten. Modellen förutser justeringar av ankarboxarna istället för att förutsäga avgränsningsrutor från grunden. Denna metod fungerar bra för att detektera objekt i olika skalor men ökar den beräkningsmässiga komplexiteten.
Ankarfria metoder
Ankarfria metoder, såsom CenterNet och FCOS (Fully Convolutional One-Stage Object Detection), eliminerar fördefinierade ankarboxar och förutser istället objektens centrum direkt. Dessa metoder erbjuder:
- Enklare modellarkitekturer;
- Snabbare inferenshastigheter;
- Förbättrad generalisering till okända objektstorlekar.

A (Anchor-baserad): förutspår förskjutningar (gröna linjer) från fördefinierade ankare (blå) för att matcha markdata (röd). B (Anchor-fri): uppskattar direkt förskjutningar från en punkt till dess gränser.
Förutsägelse av avgränsningsrutor är en viktig komponent inom objektigenkänning, där olika metoder balanserar noggrannhet och effektivitet. Anchor-baserade metoder ökar precisionen genom att använda fördefinierade former, medan anchor-fria metoder förenklar detektionen genom att direkt förutsäga objektens positioner. Förståelse för dessa tekniker underlättar utformningen av bättre system för objektigenkänning i olika tillämpningar.
1. Vilken information innehåller en bounding box-prediktion vanligtvis?
2. Vilken är den främsta fördelen med ankarbaserade metoder inom objektdetektering?
3. Vilken utmaning möter direkt regression vid prediktion av bounding boxar?
Tack för dina kommentarer!
Fråga AI
Fråga AI

Fråga vad du vill eller prova någon av de föreslagna frågorna för att starta vårt samtal
