Objektdetektering
Svep för att visa menyn
Objektdetektering är ett avgörande framsteg bortom bildklassificering och lokalisering. Medan klassificering avgör vilket objekt som finns i en bild och lokalisering identifierar var ett enskilt objekt befinner sig, utökar objektdetektering detta genom att känna igen flera objekt och deras positioner inom en bild.
Vad gör objektdetektering annorlunda?
Till skillnad från klassificering, som tilldelar en enda etikett till en hel bild, innebär objektdetektering både klassificering och lokalisering för flera objekt. En detekteringsmodell måste förutsäga avgränsningsrutor runt varje objekt och korrekt klassificera dem. Detta gör objektdetektering till en mer komplex och beräkningsintensiv uppgift än enkel klassificering.

Sliding Window-metoden och dess begränsningar
En traditionell metod för objektigenkänning är sliding window-metoden, där ett fönster med fast storlek förflyttas över en bild för att klassificera varje sektion. Trots att metoden är konceptuellt enkel har den flera begränsningar:
- Beräkningsintensiv: kräver att bilden skannas på flera skalor och positioner, vilket leder till lång bearbetningstid;
- Stela fönsterstorlekar: objekt varierar i storlek och proportioner, vilket gör fasta fönsterstorlekar ineffektiva;
- Redundanta beräkningar: överlappande fönster bearbetar upprepade gånger liknande bildområden, vilket slösar resurser.
På grund av dessa ineffektiviteter har djupinlärningsbaserade metoder för objektigenkänning till stor del ersatt sliding window-metoden.

Regionbaserade metoder: Selective Search & Region Proposal Networks (RPN)
För att förbättra effektiviteten föreslår regionbaserade metoder Regions of Interest (RoI) istället för att skanna hela bilden. Två huvudsakliga tekniker är:
-
Selective search: en traditionell metod som grupperar liknande pixlar till regionförslag, vilket minskar antalet förutsägelser av avgränsningsrutor. Även om den är mer effektiv än sliding window är den fortfarande långsam;
-
Region proposal networks (RPNs): används i Faster R-CNN, där RPNs använder ett neuralt nätverk för att direkt generera potentiella objektregioner, vilket avsevärt förbättrar hastighet och noggrannhet jämfört med selective search.
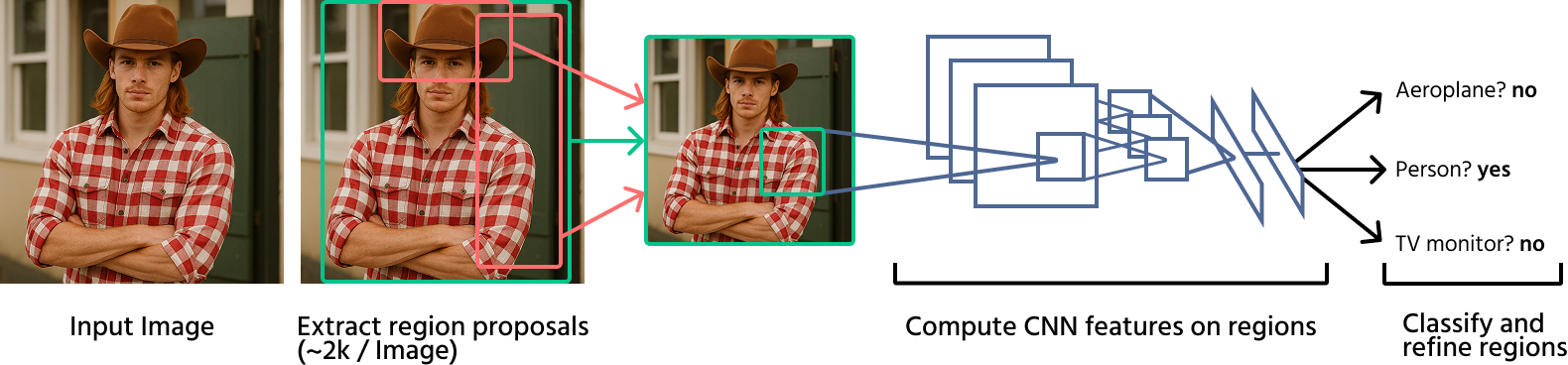
Tidiga djupinlärningsbaserade metoder
Djupinlärning revolutionerade objektigenkänning genom att introducera konvolutionella neurala nätverk (CNN) i detekteringsprocessen. Några av de banbrytande modellerna inkluderar:
-
R-CNN (Regions with CNNs): denna metod tillämpar ett CNN på varje regionförslag som genereras av selektiv sökning. Även om den är betydligt mer exakt än traditionella metoder, är den beräkningsmässigt långsam på grund av upprepade CNN-utvärderingar;
-
Fast R-CNN: en förbättring av R-CNN, denna modell bearbetar hela bilden med ett CNN först och tillämpar sedan RoI-poolning för att extrahera funktioner för klassificering, vilket snabbar upp detekteringen;
-
Faster R-CNN: introducerar regionförslagsnätverk (RPN) för att ersätta selektiv sökning, vilket gör objektigenkänning snabbare och mer exakt genom att integrera regionförslagsgenerering i det neurala nätverket självt.
Objektigenkänning bygger vidare på klassificering och lokalisering, vilket möjliggör för modeller att känna igen flera objekt i en bild. Traditionella metoder som glidande fönster har ersatts av mer effektiva regionbaserade tekniker såsom R-CNN och dess efterföljare. Faster R-CNN, med användning av regionförslagsnätverk, utgör ett betydande steg mot realtidsigenkänning med hög noggrannhet. Framöver kommer mer avancerade tekniker som YOLO och SSD ytterligare att förbättra detekteringshastighet och effektivitet.
1. Vad är den främsta fördelen med Faster R-CNN jämfört med Fast R-CNN?
2. Varför är sliding window-metoden ineffektiv för objektdetektering?
3. Vilken av följande är en djupinlärningsbaserad metod för objektdetektering?
Tack för dina kommentarer!
Fråga AI
Fråga AI

Fråga vad du vill eller prova någon av de föreslagna frågorna för att starta vårt samtal
