 K-Medoids and the Weather Data
K-Medoids and the Weather Data
As you can see, there was no such clear peek as in the example. That means that both 3 and 4 clusters may be a good choice!
Let's see what will be the result of using the K-Medoids algorithm for the weather data we used in the previous section. Let's start with defining the optimal number of clusters.
Завдання
Swipe to start coding
Given cities' average temperatures dataset data. The numerical columns are 3 - 14.
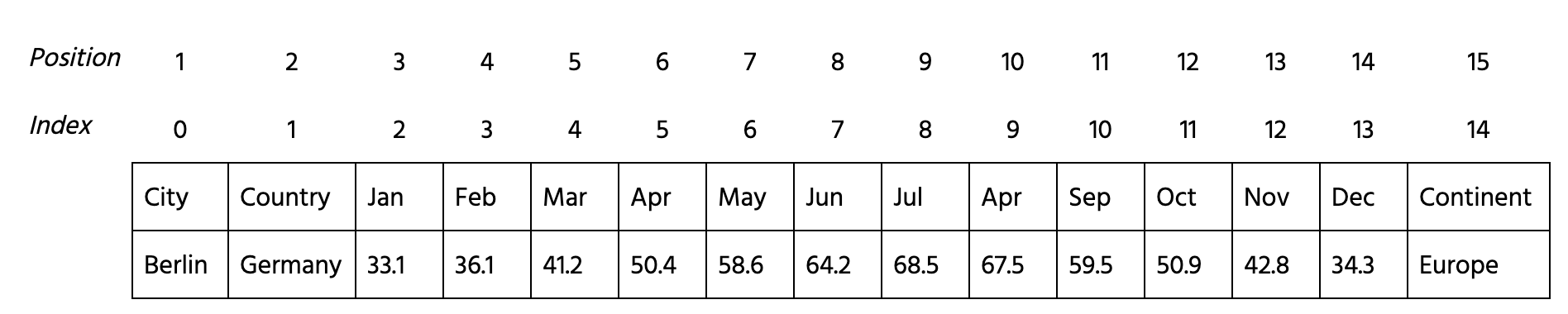
Your tasks are:
- Using
forloop iterate overn_cl. Within the loop:
- Create
KMedoidsmodel withjclusters namedmodel. - Fit the 2-15 columns of
datato the model. Watch out that indices in Python start from 0. - Add silhouette score value to the
silhouetteslist. Remember to pass two parameters: the data used for fitting (the same 3-15 columns) and predicted bymodellabels.
- Visualize the results using
lineplotofsns. Passn_clasxparameter andsilhouettesasy. Do not forget to apply the.show()method to display the plot.
Рішення
99
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# Import the libraries
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn_extra.cluster import KMedoids
from sklearn.metrics import silhouette_score
# Read the data
data = pd.read_csv('https://codefinity-content-media.s3.eu-west-1.amazonaws.com/138ab9ad-aa37-4310-873f-0f62abafb038/Cities+weather.csv', index_col = 0)
# Creating lists
n_cl = range(2, 10)
silhouettes = []
# Calculate the scores for different number of clusters
for j in n_cl:
model = KMedoids(n_clusters = j)
model.fit(data.iloc[:,2:-1])
silhouettes.append(silhouette_score(data.iloc[:,2:-1], model.labels_))
# Visualize the results
g = sns.lineplot(x = n_cl, y = silhouettes)
g.set_xlabel('Number of clusters')
g.set_ylabel('Silhouette score')
plt.show()
Все було зрозуміло?
Дякуємо за ваш відгук!
Секція 2. Розділ 4
single
99
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# Import the libraries
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn_extra.cluster import KMedoids
from sklearn.metrics import silhouette_score
# Read the data
data = pd.read_csv('https://codefinity-content-media.s3.eu-west-1.amazonaws.com/138ab9ad-aa37-4310-873f-0f62abafb038/Cities+weather.csv', index_col = 0)
# Creating lists
n_cl = range(2, 10)
silhouettes = []
# Calculate the scores for different number of clusters
for j in ___:
model = ___(___ = ___)
model.fit(data.___[:,___])
silhouettes.append(___(___.___[:,___], model.___))
# Visualize the results
g = sns.___(x = ___, y = ___)
g.set_xlabel('Number of clusters')
g.set_ylabel('Silhouette score')
___
Запитати АІ
Запитати АІ

Запитайте про що завгодно або спробуйте одне із запропонованих запитань, щоб почати наш чат
