Спільний Графік
Joint plot — це досить унікальний графік, оскільки він поєднує кілька типів графіків. Це діаграма, яка відображає взаємозв'язок між двома змінними разом з їх індивідуальними розподілами.
Joint plot поєднує три елементи:
- гістограма зверху (розподіл x-змінної);
- гістограма справа (розподіл y-змінної);
- точковий графік у центрі (взаємозв'язок між двома змінними).
Ось приклад:
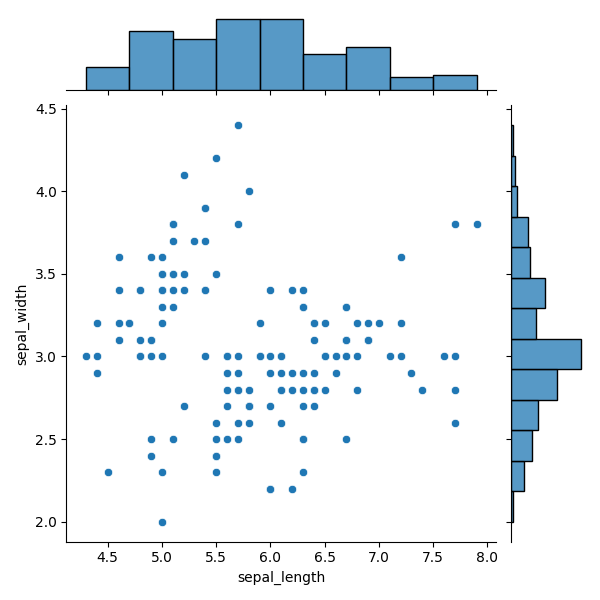
Дані для Joint Plot
seaborn.jointplot() використовує три основні параметри:
data— DataFrame,x— змінна для верхньої гістограми,y— змінна для правої гістограми.
x та y можуть бути назвами стовпців або масивоподібними об'єктами.
12345678import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris flowers species iris_df = sns.load_dataset("iris") sns.jointplot(data=iris_df, x="sepal_length", y="sepal_width") plt.show()
Цей приклад відтворюється шляхом передачі DataFrame у параметр data та зазначення назв стовпців для x і y.
Графік у центрі
Параметр kind визначає тип центрального графіка.
За замовчуванням: 'scatter'.
Інші варіанти: 'kde', 'hist', 'hex', 'reg', 'resid'.
12345678import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris flowers species iris_df = sns.load_dataset("iris") sns.jointplot(data=iris_df, x="sepal_length", y="sepal_width", kind='reg') plt.show()
Типи графіків
Окрім scatter, можна обрати:
- reg — додає лінійну регресійну пряму;
- resid — будує залишки регресії;
- hist — двовимірна гістограма;
- kde — двозмінна оцінка щільності ядра (KDE);
- hex — hexbin-графік, що відображає щільність за допомогою кольорових шестикутних бінів.
Як завжди, можна ознайомитися з додатковими параметрами та опціями у документації jointplot().
Також рекомендується ознайомитися з наступними темами:
документації residplot();
Приклад двовимірної гістограми;
Приклад hexbin-графіка.
Дякуємо за ваш відгук!
single
Спільний Графік
Свайпніть щоб показати меню
Joint plot — це досить унікальний графік, оскільки він поєднує кілька типів графіків. Це діаграма, яка відображає взаємозв'язок між двома змінними разом з їх індивідуальними розподілами.
Joint plot поєднує три елементи:
- гістограма зверху (розподіл x-змінної);
- гістограма справа (розподіл y-змінної);
- точковий графік у центрі (взаємозв'язок між двома змінними).
Ось приклад:
Дані для Joint Plot
seaborn.jointplot() використовує три основні параметри:
data— DataFrame,x— змінна для верхньої гістограми,y— змінна для правої гістограми.
x та y можуть бути назвами стовпців або масивоподібними об'єктами.
12345678import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris flowers species iris_df = sns.load_dataset("iris") sns.jointplot(data=iris_df, x="sepal_length", y="sepal_width") plt.show()
Цей приклад відтворюється шляхом передачі DataFrame у параметр data та зазначення назв стовпців для x і y.
Графік у центрі
Параметр kind визначає тип центрального графіка.
За замовчуванням: 'scatter'.
Інші варіанти: 'kde', 'hist', 'hex', 'reg', 'resid'.
12345678import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris flowers species iris_df = sns.load_dataset("iris") sns.jointplot(data=iris_df, x="sepal_length", y="sepal_width", kind='reg') plt.show()
Типи графіків
Окрім scatter, можна обрати:
- reg — додає лінійну регресійну пряму;
- resid — будує залишки регресії;
- hist — двовимірна гістограма;
- kde — двозмінна оцінка щільності ядра (KDE);
- hex — hexbin-графік, що відображає щільність за допомогою кольорових шестикутних бінів.
Як завжди, можна ознайомитися з додатковими параметрами та опціями у документації jointplot().
Також рекомендується ознайомитися з наступними темами:
документації residplot();
Приклад двовимірної гістограми;
Приклад hexbin-графіка.
Проведіть, щоб почати кодувати
- Використати відповідну функцію для створення спільного графіка.
- Використати
weather_dfяк дані для побудови графіка (перший аргумент). - Встановити стовпець
'Boston'як змінну для осі x (другий аргумент). - Встановити стовпець
'Seattle'як змінну для осі y (третій аргумент). - Встановити на центральному графіку лінію регресії (крайній правий аргумент).
Рішення
Дякуємо за ваш відгук!
single
Запитати АІ
Запитати АІ

Запитайте про що завгодно або спробуйте одне із запропонованих запитань, щоб почати наш чат
