Огляд Функцій Активації
Свайпніть щоб показати меню
Чому функції активації є критично важливими в CNN
Функції активації вводять нелінійність у згорткові нейронні мережі (CNN), дозволяючи їм вивчати складні закономірності, які недоступні простим лінійним моделям. Без функцій активації CNN не змогли б виявляти складні взаємозв'язки в даних, що обмежує їхню ефективність у розпізнаванні та класифікації зображень. Вибір правильної функції активації впливає на швидкість навчання, стабільність та загальну продуктивність.
Поширені функції активації
- ReLU (rectified linear unit): найпоширеніша функція активації в CNN. Пропускає лише додатні значення, встановлюючи всі від’ємні входи в нуль, що забезпечує обчислювальну ефективність і запобігає зникненню градієнтів. Однак деякі нейрони можуть стати неактивними через проблему "вимирання ReLU";

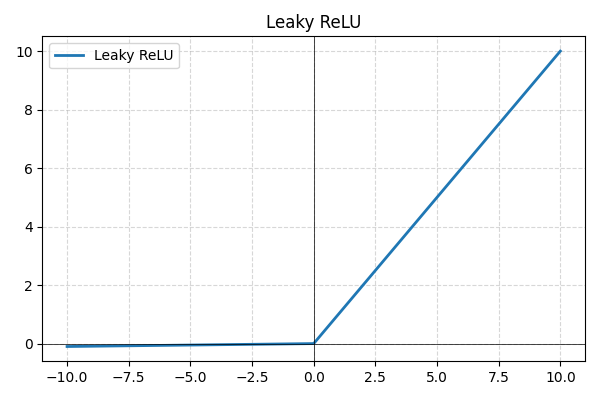
- Leaky ReLU: варіація ReLU, яка дозволяє невеликі від’ємні значення замість встановлення їх у нуль, запобігаючи неактивності нейронів і покращуючи проходження градієнта;
- Сигмоїда: стискає вхідні значення до діапазону від 0 до 1, що робить її корисною для бінарної класифікації. Однак у глибоких мережах виникає проблема зникнення градієнтів;

- Tanh: подібна до сигмоїди, але повертає значення в діапазоні від -1 до 1, центровані навколо нуля;

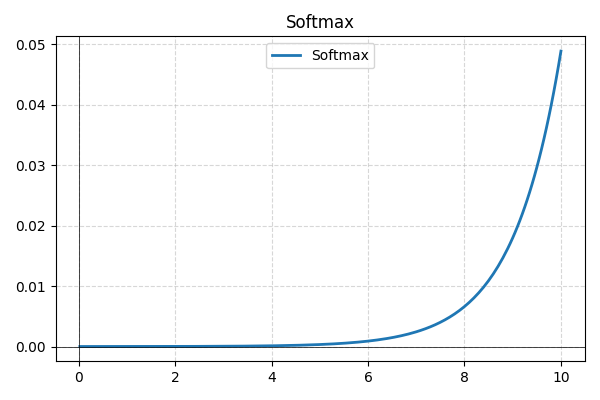
- Softmax: зазвичай використовується на фінальному шарі для багатокласової класифікації, Softmax перетворює сирі вихідні дані мережі у ймовірності, забезпечуючи їхню суму до одиниці для кращої інтерпретації.
Вибір відповідної функції активації
ReLU є типовим вибором для прихованих шарів завдяки своїй ефективності та високій продуктивності, тоді як Leaky ReLU краще підходить у випадках неактивності нейронів. Sigmoid та Tanh зазвичай уникають у глибоких CNN, але вони можуть бути корисними для окремих застосувань. Softmax залишається необхідною для задач багатокласової класифікації, забезпечуючи чіткі ймовірнісні передбачення.
Вибір правильної функції активації є ключовим для оптимізації продуктивності CNN, балансу ефективності та запобігання таким проблемам, як зникнення або вибух градієнтів. Кожна функція по-своєму впливає на те, як мережа обробляє та навчається на візуальних даних.
1. Чому ReLU віддають перевагу над Sigmoid у глибоких CNN?
2. Яка функція активації зазвичай використовується на фінальному шарі багатокласової класифікаційної CNN?
3. Яка основна перевага Leaky ReLU над стандартною ReLU?
Дякуємо за ваш відгук!
Запитати АІ
Запитати АІ

Запитайте про що завгодно або спробуйте одне із запропонованих запитань, щоб почати наш чат
Огляд Функцій Активації
Чому функції активації є критично важливими в CNN
Функції активації вводять нелінійність у згорткові нейронні мережі (CNN), дозволяючи їм вивчати складні закономірності, які недоступні простим лінійним моделям. Без функцій активації CNN не змогли б виявляти складні взаємозв'язки в даних, що обмежує їхню ефективність у розпізнаванні та класифікації зображень. Вибір правильної функції активації впливає на швидкість навчання, стабільність та загальну продуктивність.
Поширені функції активації
- ReLU (rectified linear unit): найпоширеніша функція активації в CNN. Пропускає лише додатні значення, встановлюючи всі від’ємні входи в нуль, що забезпечує обчислювальну ефективність і запобігає зникненню градієнтів. Однак деякі нейрони можуть стати неактивними через проблему "вимирання ReLU";
- Leaky ReLU: варіація ReLU, яка дозволяє невеликі від’ємні значення замість встановлення їх у нуль, запобігаючи неактивності нейронів і покращуючи проходження градієнта;
- Сигмоїда: стискає вхідні значення до діапазону від 0 до 1, що робить її корисною для бінарної класифікації. Однак у глибоких мережах виникає проблема зникнення градієнтів;
- Tanh: подібна до сигмоїди, але повертає значення в діапазоні від -1 до 1, центровані навколо нуля;
- Softmax: зазвичай використовується на фінальному шарі для багатокласової класифікації, Softmax перетворює сирі вихідні дані мережі у ймовірності, забезпечуючи їхню суму до одиниці для кращої інтерпретації.
Вибір відповідної функції активації
ReLU є типовим вибором для прихованих шарів завдяки своїй ефективності та високій продуктивності, тоді як Leaky ReLU краще підходить у випадках неактивності нейронів. Sigmoid та Tanh зазвичай уникають у глибоких CNN, але вони можуть бути корисними для окремих застосувань. Softmax залишається необхідною для задач багатокласової класифікації, забезпечуючи чіткі ймовірнісні передбачення.
Вибір правильної функції активації є ключовим для оптимізації продуктивності CNN, балансу ефективності та запобігання таким проблемам, як зникнення або вибух градієнтів. Кожна функція по-своєму впливає на те, як мережа обробляє та навчається на візуальних даних.
Дякуємо за ваш відгук!
