Реалізація Word2Vec
Свайпніть щоб показати меню
Зрозумівши принцип роботи Word2Vec, перейдемо до його реалізації за допомогою Python. Бібліотека Gensim, потужний інструмент з відкритим кодом для обробки природної мови, надає зручну реалізацію через клас Word2Vec у модулі gensim.models.
Підготовка даних
Word2Vec вимагає, щоб текстові дані були токенізовані, тобто розбиті на список списків, де кожен внутрішній список містить слова з окремого речення. У цьому прикладі ми використаємо роман Emma англійської письменниці Jane Austen як наш корпус. Ми завантажимо CSV-файл, що містить попередньо оброблені речення, а потім розіб'ємо кожне речення на слова:
12345678import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') # Split each sentence into words sentences = emma_df['Sentence'].str.split() # Print the fourth sentence (list of words) print(sentences[3])
emma_df['Sentence'].str.split() застосовує метод .split() до кожного речення у стовпці 'Sentence', у результаті чого для кожного речення формується список слів. Оскільки речення вже були попередньо оброблені, а слова відокремлені пробілами, методу .split() достатньо для цієї токенізації.
Навчання моделі Word2Vec
Тепер зосередимося на навчанні моделі Word2Vec з використанням токенізованих даних. Клас Word2Vec пропонує різноманітні параметри для налаштування. Однак найчастіше використовуються такі параметри:
vector_size(за замовчуванням 100): розмірність або розмір векторних представлень слів;window(за замовчуванням 5): розмір контекстного вікна;min_count(за замовчуванням 5): слова, що зустрічаються рідше цієї кількості, ігноруються;sg(за замовчуванням 0): архітектура моделі (1 — Skip-gram, 0 — CBoW).cbow_mean(за замовчуванням 1): визначає, чи контекст CBoW підсумовується (0) чи усереднюється (1)
Щодо архітектур моделі, CBoW підходить для більших наборів даних і ситуацій, коли важлива обчислювальна ефективність. Skip-gram, навпаки, краще підходить для завдань, що потребують детального розуміння контексту слів, особливо ефективний на менших наборах даних або при роботі з рідкісними словами.
12345678from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() # Initialize the model model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0)
Тут розмір векторного представлення встановлено на 200, розмір контекстного вікна — на 5, а всі слова включені шляхом встановлення min_count=1. Встановивши sg=0, обрано модель CBoW.
Вибір оптимального розміру векторного представлення та контекстного вікна потребує компромісів. Більші вектори краще відображають значення, але збільшують обчислювальні витрати та ризик перенавчання. Менші контекстні вікна краще фіксують синтаксис, тоді як більші — семантику.
Пошук схожих слів
Після того як слова представлені у вигляді векторів, їх можна порівнювати для вимірювання схожості. Хоча можна використовувати відстань, напрямок вектора часто несе більше семантичного значення, ніж його довжина, особливо у векторних представленнях слів.
Однак використання кута як метрики схожості не є зручним. Замість цього можна використовувати косинус кута між двома векторами, також відомий як косинусна схожість. Її значення лежить у межах від -1 до 1, де більші значення вказують на більшу схожість. Такий підхід фокусується на узгодженості напрямків векторів незалежно від їхньої довжини, що ідеально підходить для порівняння значень слів. Нижче наведено ілюстрацію:
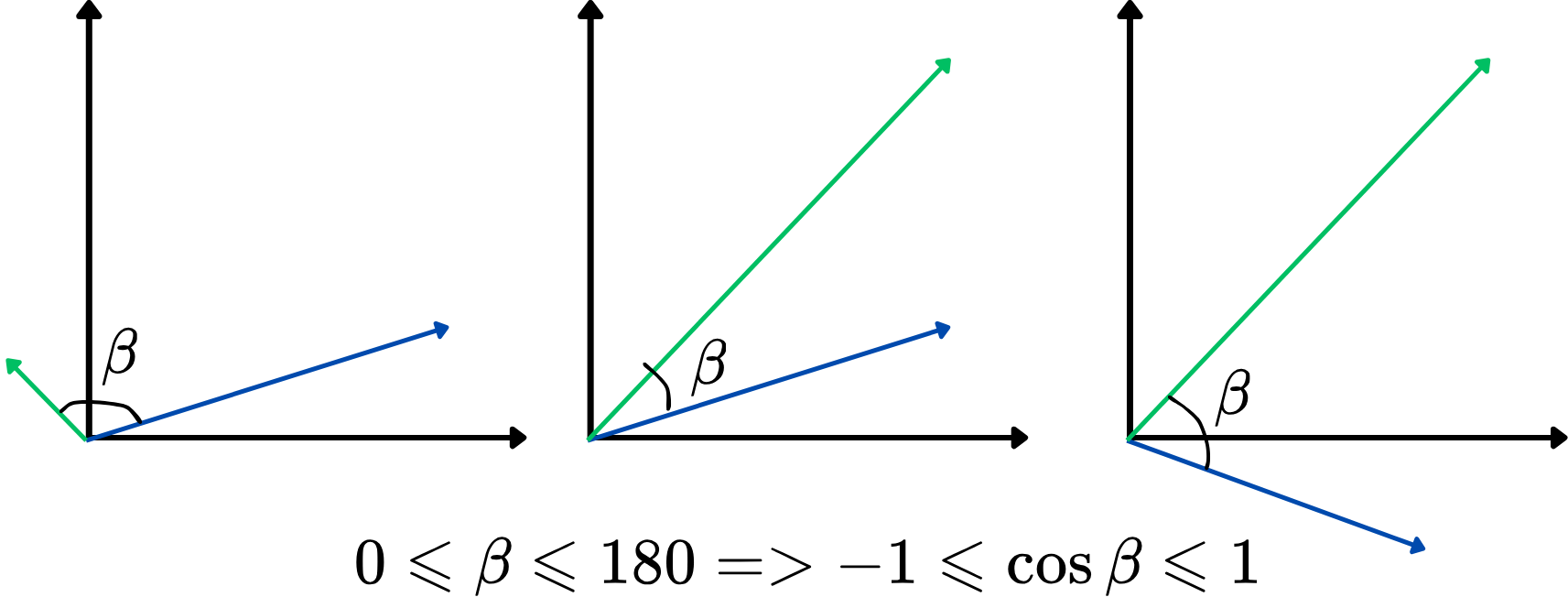
Чим вища косинусна схожість, тим більш подібними є два вектори, і навпаки. Наприклад, якщо два вектори слів мають косинусну схожість, близьку до 1 (кут близький до 0 градусів), це вказує на їхню тісну спорідненість або схожість у контексті векторного простору.
Тепер знайдемо топ-5 найбільш схожих слів до слова "man" за допомогою косинусної схожості:
12345678910from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0) # Retrieve the top-5 most similar words to 'man' similar_words = model.wv.most_similar('man', topn=5) print(similar_words)
model.wv надає доступ до векторів слів натренованої моделі, а метод .most_similar() знаходить слова, векторні представлення яких найближчі до векторного представлення вказаного слова на основі косинусної схожості. Параметр topn визначає кількість top-N подібних слів, які буде повернуто.
Дякуємо за ваш відгук!
Запитати АІ
Запитати АІ

Запитайте про що завгодно або спробуйте одне із запропонованих запитань, щоб почати наш чат
Реалізація Word2Vec
Зрозумівши принцип роботи Word2Vec, перейдемо до його реалізації за допомогою Python. Бібліотека Gensim, потужний інструмент з відкритим кодом для обробки природної мови, надає зручну реалізацію через клас Word2Vec у модулі gensim.models.
Підготовка даних
Word2Vec вимагає, щоб текстові дані були токенізовані, тобто розбиті на список списків, де кожен внутрішній список містить слова з окремого речення. У цьому прикладі ми використаємо роман Emma англійської письменниці Jane Austen як наш корпус. Ми завантажимо CSV-файл, що містить попередньо оброблені речення, а потім розіб'ємо кожне речення на слова:
12345678import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') # Split each sentence into words sentences = emma_df['Sentence'].str.split() # Print the fourth sentence (list of words) print(sentences[3])
emma_df['Sentence'].str.split() застосовує метод .split() до кожного речення у стовпці 'Sentence', у результаті чого для кожного речення формується список слів. Оскільки речення вже були попередньо оброблені, а слова відокремлені пробілами, методу .split() достатньо для цієї токенізації.
Навчання моделі Word2Vec
Тепер зосередимося на навчанні моделі Word2Vec з використанням токенізованих даних. Клас Word2Vec пропонує різноманітні параметри для налаштування. Однак найчастіше використовуються такі параметри:
vector_size(за замовчуванням 100): розмірність або розмір векторних представлень слів;window(за замовчуванням 5): розмір контекстного вікна;min_count(за замовчуванням 5): слова, що зустрічаються рідше цієї кількості, ігноруються;sg(за замовчуванням 0): архітектура моделі (1 — Skip-gram, 0 — CBoW).cbow_mean(за замовчуванням 1): визначає, чи контекст CBoW підсумовується (0) чи усереднюється (1)
Щодо архітектур моделі, CBoW підходить для більших наборів даних і ситуацій, коли важлива обчислювальна ефективність. Skip-gram, навпаки, краще підходить для завдань, що потребують детального розуміння контексту слів, особливо ефективний на менших наборах даних або при роботі з рідкісними словами.
12345678from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() # Initialize the model model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0)
Тут розмір векторного представлення встановлено на 200, розмір контекстного вікна — на 5, а всі слова включені шляхом встановлення min_count=1. Встановивши sg=0, обрано модель CBoW.
Вибір оптимального розміру векторного представлення та контекстного вікна потребує компромісів. Більші вектори краще відображають значення, але збільшують обчислювальні витрати та ризик перенавчання. Менші контекстні вікна краще фіксують синтаксис, тоді як більші — семантику.
Пошук схожих слів
Після того як слова представлені у вигляді векторів, їх можна порівнювати для вимірювання схожості. Хоча можна використовувати відстань, напрямок вектора часто несе більше семантичного значення, ніж його довжина, особливо у векторних представленнях слів.
Однак використання кута як метрики схожості не є зручним. Замість цього можна використовувати косинус кута між двома векторами, також відомий як косинусна схожість. Її значення лежить у межах від -1 до 1, де більші значення вказують на більшу схожість. Такий підхід фокусується на узгодженості напрямків векторів незалежно від їхньої довжини, що ідеально підходить для порівняння значень слів. Нижче наведено ілюстрацію:
Чим вища косинусна схожість, тим більш подібними є два вектори, і навпаки. Наприклад, якщо два вектори слів мають косинусну схожість, близьку до 1 (кут близький до 0 градусів), це вказує на їхню тісну спорідненість або схожість у контексті векторного простору.
Тепер знайдемо топ-5 найбільш схожих слів до слова "man" за допомогою косинусної схожості:
12345678910from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0) # Retrieve the top-5 most similar words to 'man' similar_words = model.wv.most_similar('man', topn=5) print(similar_words)
model.wv надає доступ до векторів слів натренованої моделі, а метод .most_similar() знаходить слова, векторні представлення яких найближчі до векторного представлення вказаного слова на основі косинусної схожості. Параметр topn визначає кількість top-N подібних слів, які буде повернуто.
Дякуємо за ваш відгук!
