Огляд Генерації Зображень
Свайпніть щоб показати меню
Зображення, створені штучним інтелектом, змінюють підходи до створення мистецтва, дизайну та цифрового контенту. За допомогою штучного інтелекту комп’ютери тепер можуть створювати реалістичні зображення, підсилювати творчі процеси та навіть допомагати бізнесу. У цьому розділі розглядаються принципи створення зображень за допомогою ШІ, різновиди моделей для генерації зображень і їхнє застосування на практиці.
Як ШІ створює зображення
Генерація зображень за допомогою ШІ працює шляхом навчання на великій кількості зображень. ШІ аналізує закономірності у зображеннях і створює нові, схожі на них. З роками ця технологія значно вдосконалилася, дозволяючи отримувати більш реалістичні та креативні зображення. Сьогодні її використовують у відеоіграх, кіно, рекламі та навіть у моді.
Перші методи: PixelRNN і PixelCNN
До появи сучасних моделей ШІ дослідники створили перші методи генерації зображень, такі як PixelRNN і PixelCNN. Ці моделі створювали зображення, передбачаючи кожен піксель окремо.
- PixelRNN: використовує систему, що називається рекурентною нейронною мережею (RNN), для поетапного передбачення кольорів пікселів. Хоча цей підхід був ефективним, він працював дуже повільно;
- PixelCNN: удосконалив PixelRNN завдяки використанню іншого типу мережі — згорткових шарів, що прискорило процес створення зображень.
Попри те, що ці моделі стали важливим кроком уперед, вони не забезпечували високу якість зображень. Це стимулювало розвиток більш досконалих технологій.
Авторегресивні моделі
Авторегресивні моделі також створюють зображення по одному пікселю, використовуючи попередні пікселі для прогнозування наступного. Такі моделі були корисними, але повільними, що з часом зробило їх менш популярними. Проте вони стали натхненням для новіших, швидших моделей.
Як ШІ розуміє текст для створення зображень
Деякі моделі ШІ можуть перетворювати текстові описи на зображення. Такі моделі використовують великі мовні моделі (LLM) для розуміння описів і генерації відповідних зображень. Наприклад, якщо ввести «кіт, що сидить на пляжі на заході сонця», ШІ створить зображення на основі цього опису.
Моделі ШІ, такі як DALL-E від OpenAI та Imagen від Google, використовують розвинене розуміння мови для покращення відповідності між текстовими описами та згенерованими зображеннями. Це можливо завдяки обробці природної мови (NLP), яка допомагає ШІ перетворювати слова на числа, що керують створенням зображень.
Генеративно-змагальні мережі (GAN)
Одним із найважливіших проривів у генерації зображень за допомогою ШІ стали генеративно-змагальні мережі (GAN). GAN працюють за допомогою двох різних нейронних мереж:
- Генератор: створює нові зображення з нуля;
- Дискримінатор: перевіряє, чи виглядають зображення справжніми чи підробленими.
Генератор намагається створити настільки реалістичні зображення, щоб дискримінатор не міг відрізнити їх від справжніх. З часом зображення стають кращими та схожими на справжні фотографії. GAN використовуються у технологіях deepfake, створенні мистецтва та покращенні якості зображень.
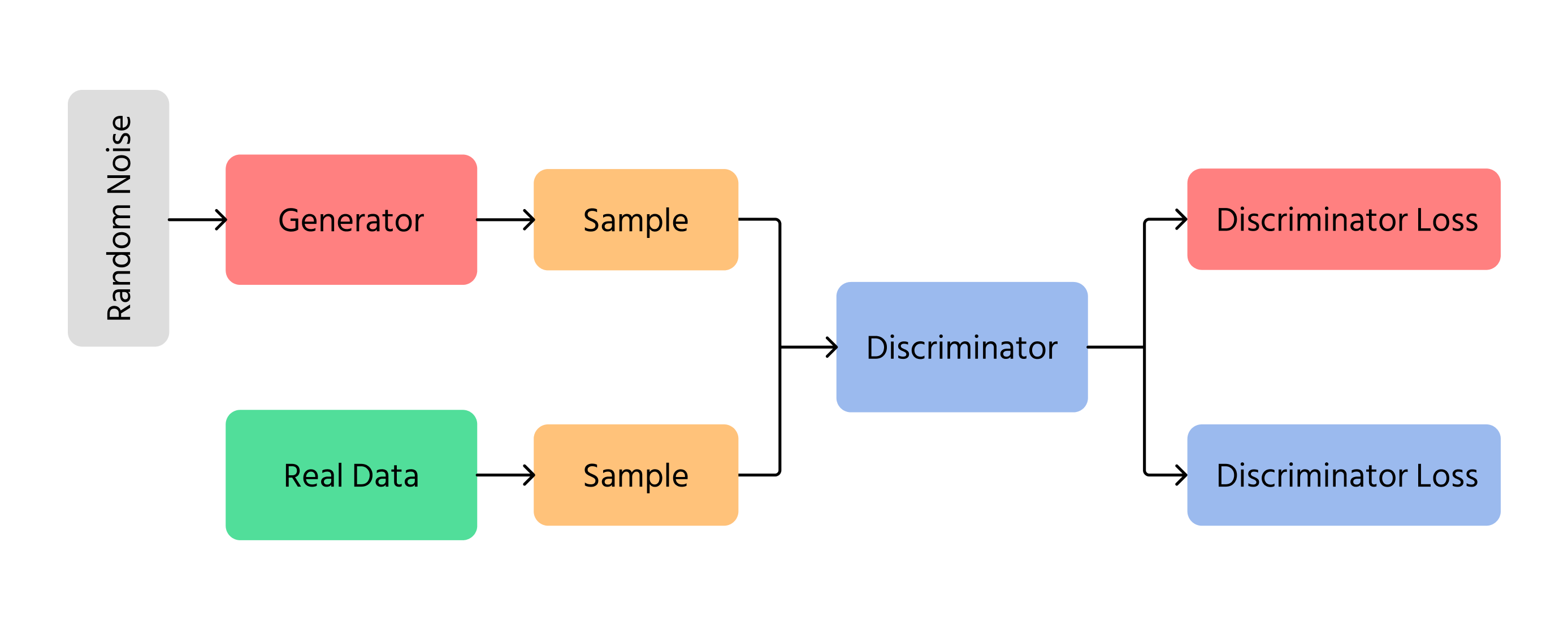
Варіаційні автокодери (VAE)
VAE — це ще один спосіб генерації зображень за допомогою штучного інтелекту. Замість використання змагання, як у GAN, VAE кодують і декодують зображення з використанням ймовірності. Вони працюють шляхом вивчення прихованих закономірностей у зображенні та подальшої реконструкції з невеликими варіаціями. Ймовірнісний підхід у VAE гарантує, що кожне згенероване зображення буде трохи відрізнятися, що додає різноманіття та креативності.
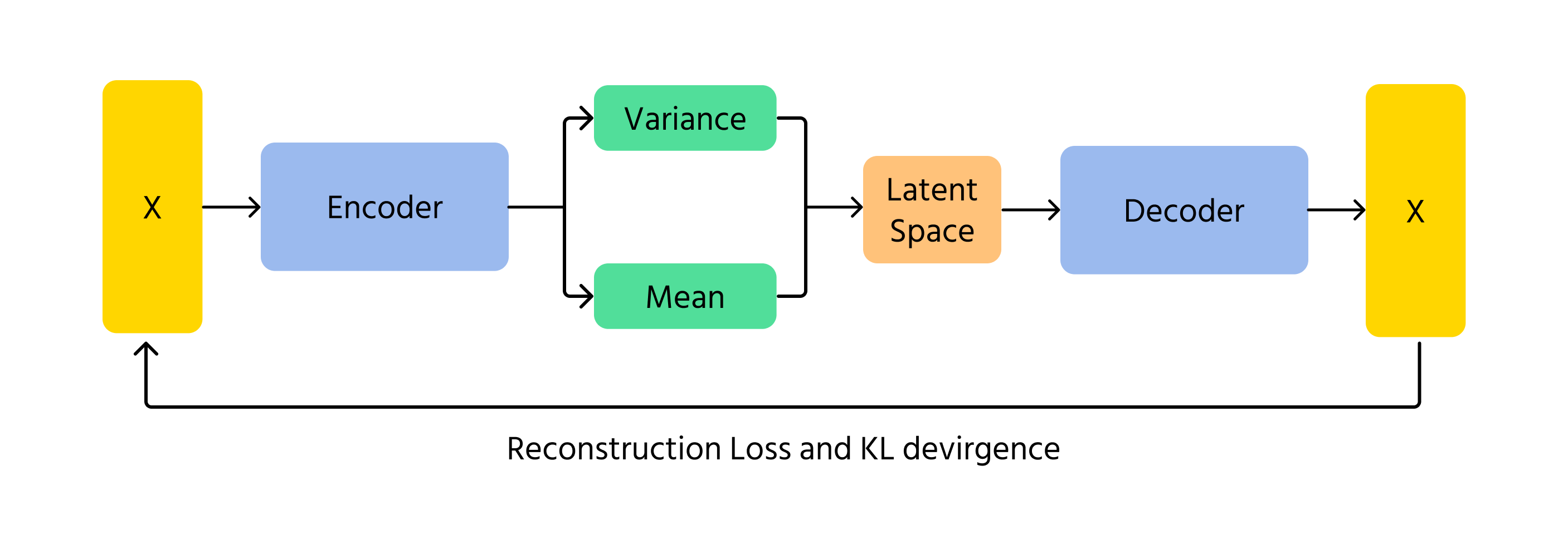
Ключовим поняттям у VAE є дивергенція Кульбака-Лейблера (KL-розбіжність), яка вимірює різницю між вивченою розподільною функцією та стандартним нормальним розподілом. Мінімізуючи KL-розбіжність, VAE забезпечують реалістичність згенерованих зображень, водночас дозволяючи творчі варіації.
Принцип роботи VAE
- Кодування: вхідні дані x подаються на кодувальник, який видає параметри розподілу латентного простору q(z∣x) (середнє μ та дисперсія σ²);
- Вибірка з латентного простору: латентні змінні z вибираються з розподілу q(z∣x) з використанням таких технік, як трюк репараметризації;
- Декодування та реконструкція: вибране z передається через декодер для отримання реконструйованих даних x̂, які мають бути схожими на оригінальний вхід x.
VAE корисні для завдань, таких як реконструкція облич, генерація нових версій існуючих зображень і плавні переходи між різними картинками.
Диффузійні моделі
Диффузійні моделі — це найновіший прорив у створенні зображень за допомогою ШІ. Такі моделі починають із випадкового шуму й поступово покращують зображення крок за кроком, ніби стираючи перешкоди з розмитої фотографії. На відміну від GAN, які іноді створюють обмежені варіації, диффузійні моделі здатні генерувати ширший спектр якісних зображень.
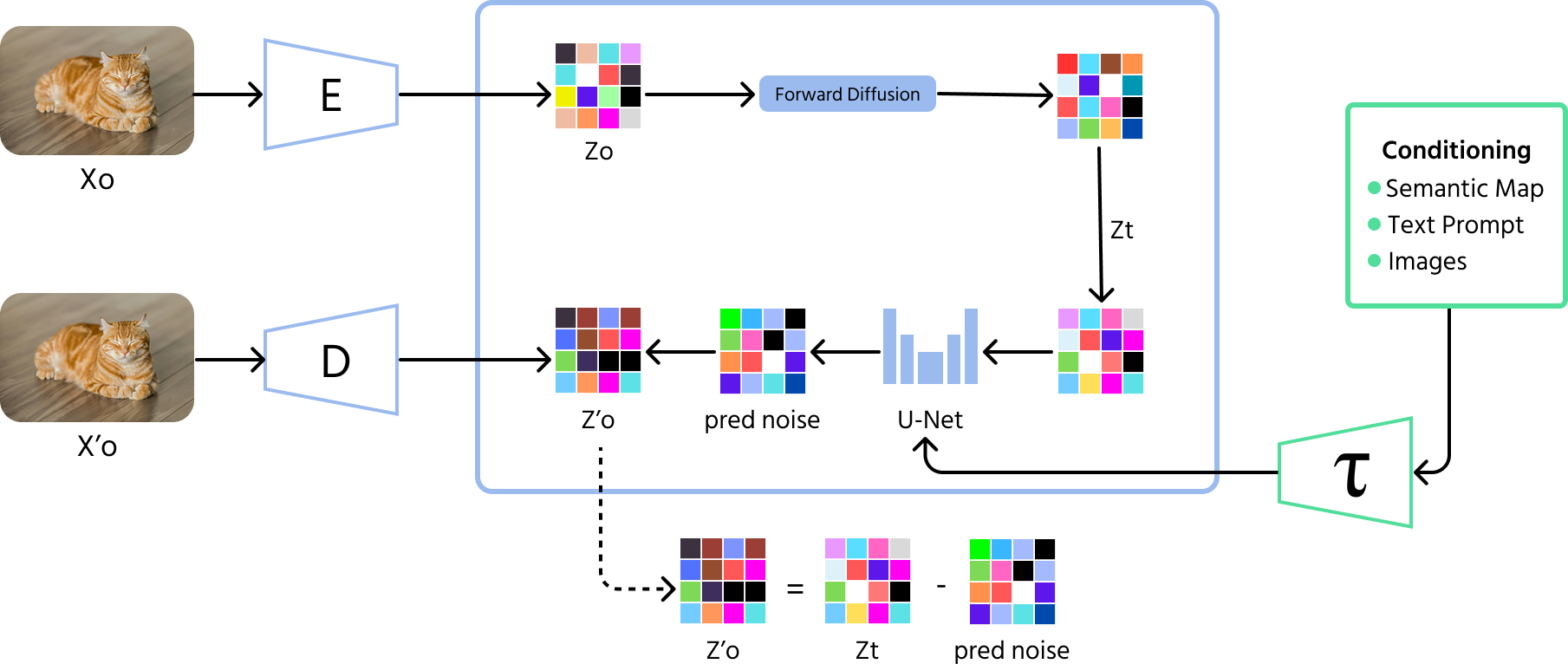
Як працюють дифузійні моделі
- Прямий процес (додавання шуму): модель починає з додавання випадкового шуму до зображення протягом багатьох кроків, поки воно не стане повністю невпізнаваним;
- Зворотний процес (видалення шуму): далі модель навчається зворотному процесу, поступово видаляючи шум крок за кроком, щоб відновити змістовне зображення;
- Навчання: дифузійні моделі навчаються передбачати та видаляти шум на кожному кроці, що дозволяє їм генерувати чіткі та якісні зображення з випадкового шуму.
Популярними прикладами є MidJourney, DALL-E та Stable Diffusion, які відомі створенням реалістичних і художніх зображень. Дифузійні моделі широко використовуються для AI-генерованого мистецтва, синтезу зображень високої роздільної здатності та креативного дизайну.
Приклади зображень, згенерованих дифузійними моделями

Реалістичне зображення баскетболіста з бородою у жовто-фіолетовій формі, який виконує данк і перемагає демонів у баскетбольній грі; вся дія відбувається в пеклі.

Сюрреалістична красива художня фотографія білого Volkswagen Golf GTI 1990 року на безкрайньому полі білих квітів у гармонії з природою, серед безмежних пагорбів, вкритих квітами; ботанічний стиль, природне освітлення, художній ефект, туман, фотореалістичний сюрреалізм, ультра деталізація, плівка Kodak, природне світло, ширококутний об'єктив, f 1.20

Картина бежевого пуделя, що лежить на зеленому дивані з зелено-білою смугастою подушкою у стилі Ферфілда Портера, абстрактний експресіонізм, з виразними мазками на бежевому тлі

Екстремальний крупний план шкіри жінки середземноморського або латиноамериканського походження, що підкреслює комбінований тип шкіри з помітною жирністю на лобі та носі, тоді як щоки виглядають сухішими та злегка лущаться. Пори більш помітні в Т-зоні, а природний блиск відображає вироблення шкірного сала. Шкіра має поєднання теплих і золотистих підтонов, з нерівномірною текстурою через різний рівень зволоження. М'яке природне освітлення підкреслює реалістичний контраст між сухими та жирними ділянками. Тло розмите, акцент зосереджено на її кольорі обличчя.
Виклики та етичні питання
Попри те, що зображення, створені штучним інтелектом, вражають, вони мають виклики:
- Відсутність контролю: ШІ не завжди генерує саме те, що потрібно користувачу;
- Обчислювальні ресурси: створення якісних зображень за допомогою ШІ потребує дорогого та потужного обладнання;
- Упередженість моделей ШІ: оскільки ШІ навчається на існуючих зображеннях, він може повторювати упередження, що містяться в даних.
Існують також етичні питання:
- Кому належить мистецтво ШІ?: якщо ШІ створює твір мистецтва, чи належить він людині, яка використала ШІ, чи компанії-розробнику?
- Фейкові зображення та дипфейки: GAN можуть використовуватися для створення фейкових зображень, що виглядають реалістично, що може призводити до дезінформації та проблем із приватністю.
Сучасне використання генерації зображень ШІ
Зображення, створені штучним інтелектом, вже мають значний вплив у різних галузях:
- Індустрія розваг: відеоігри, кіно та анімація використовують ШІ для створення фону, персонажів і спецефектів;
- Мода: дизайнери застосовують ШІ для створення нових стилів одягу, а онлайн-магазини — для віртуальних примірок;
- Графічний дизайн: ШІ допомагає художникам і дизайнерам швидко створювати логотипи, постери та маркетингові матеріали.
Майбутнє генерації зображень за допомогою ШІ
Оскільки генерація зображень за допомогою ШІ постійно вдосконалюється, вона продовжить змінювати способи створення та використання зображень. У мистецтві, бізнесі чи розвагах ШІ відкриває нові можливості та робить творчу роботу простішою й захопливішою.
1. Яка основна мета генерації зображень за допомогою ШІ?
2. Як працюють генеративно-змагальні мережі (GANs)?
3. Яка модель ШІ починає з випадкового шуму та покращує зображення крок за кроком?
Дякуємо за ваш відгук!
Запитати АІ
Запитати АІ

Запитайте про що завгодно або спробуйте одне із запропонованих запитань, щоб почати наш чат
Огляд Генерації Зображень
Зображення, створені штучним інтелектом, змінюють підходи до створення мистецтва, дизайну та цифрового контенту. За допомогою штучного інтелекту комп’ютери тепер можуть створювати реалістичні зображення, підсилювати творчі процеси та навіть допомагати бізнесу. У цьому розділі розглядаються принципи створення зображень за допомогою ШІ, різновиди моделей для генерації зображень і їхнє застосування на практиці.
Як ШІ створює зображення
Генерація зображень за допомогою ШІ працює шляхом навчання на великій кількості зображень. ШІ аналізує закономірності у зображеннях і створює нові, схожі на них. З роками ця технологія значно вдосконалилася, дозволяючи отримувати більш реалістичні та креативні зображення. Сьогодні її використовують у відеоіграх, кіно, рекламі та навіть у моді.
Перші методи: PixelRNN і PixelCNN
До появи сучасних моделей ШІ дослідники створили перші методи генерації зображень, такі як PixelRNN і PixelCNN. Ці моделі створювали зображення, передбачаючи кожен піксель окремо.
- PixelRNN: використовує систему, що називається рекурентною нейронною мережею (RNN), для поетапного передбачення кольорів пікселів. Хоча цей підхід був ефективним, він працював дуже повільно;
- PixelCNN: удосконалив PixelRNN завдяки використанню іншого типу мережі — згорткових шарів, що прискорило процес створення зображень.
Попри те, що ці моделі стали важливим кроком уперед, вони не забезпечували високу якість зображень. Це стимулювало розвиток більш досконалих технологій.
Авторегресивні моделі
Авторегресивні моделі також створюють зображення по одному пікселю, використовуючи попередні пікселі для прогнозування наступного. Такі моделі були корисними, але повільними, що з часом зробило їх менш популярними. Проте вони стали натхненням для новіших, швидших моделей.
Як ШІ розуміє текст для створення зображень
Деякі моделі ШІ можуть перетворювати текстові описи на зображення. Такі моделі використовують великі мовні моделі (LLM) для розуміння описів і генерації відповідних зображень. Наприклад, якщо ввести «кіт, що сидить на пляжі на заході сонця», ШІ створить зображення на основі цього опису.
Моделі ШІ, такі як DALL-E від OpenAI та Imagen від Google, використовують розвинене розуміння мови для покращення відповідності між текстовими описами та згенерованими зображеннями. Це можливо завдяки обробці природної мови (NLP), яка допомагає ШІ перетворювати слова на числа, що керують створенням зображень.
Генеративно-змагальні мережі (GAN)
Одним із найважливіших проривів у генерації зображень за допомогою ШІ стали генеративно-змагальні мережі (GAN). GAN працюють за допомогою двох різних нейронних мереж:
- Генератор: створює нові зображення з нуля;
- Дискримінатор: перевіряє, чи виглядають зображення справжніми чи підробленими.
Генератор намагається створити настільки реалістичні зображення, щоб дискримінатор не міг відрізнити їх від справжніх. З часом зображення стають кращими та схожими на справжні фотографії. GAN використовуються у технологіях deepfake, створенні мистецтва та покращенні якості зображень.
Варіаційні автокодери (VAE)
VAE — це ще один спосіб генерації зображень за допомогою штучного інтелекту. Замість використання змагання, як у GAN, VAE кодують і декодують зображення з використанням ймовірності. Вони працюють шляхом вивчення прихованих закономірностей у зображенні та подальшої реконструкції з невеликими варіаціями. Ймовірнісний підхід у VAE гарантує, що кожне згенероване зображення буде трохи відрізнятися, що додає різноманіття та креативності.
Ключовим поняттям у VAE є дивергенція Кульбака-Лейблера (KL-розбіжність), яка вимірює різницю між вивченою розподільною функцією та стандартним нормальним розподілом. Мінімізуючи KL-розбіжність, VAE забезпечують реалістичність згенерованих зображень, водночас дозволяючи творчі варіації.
Принцип роботи VAE
- Кодування: вхідні дані x подаються на кодувальник, який видає параметри розподілу латентного простору q(z∣x) (середнє μ та дисперсія σ²);
- Вибірка з латентного простору: латентні змінні z вибираються з розподілу q(z∣x) з використанням таких технік, як трюк репараметризації;
- Декодування та реконструкція: вибране z передається через декодер для отримання реконструйованих даних x̂, які мають бути схожими на оригінальний вхід x.
VAE корисні для завдань, таких як реконструкція облич, генерація нових версій існуючих зображень і плавні переходи між різними картинками.
Диффузійні моделі
Диффузійні моделі — це найновіший прорив у створенні зображень за допомогою ШІ. Такі моделі починають із випадкового шуму й поступово покращують зображення крок за кроком, ніби стираючи перешкоди з розмитої фотографії. На відміну від GAN, які іноді створюють обмежені варіації, диффузійні моделі здатні генерувати ширший спектр якісних зображень.
Як працюють дифузійні моделі
- Прямий процес (додавання шуму): модель починає з додавання випадкового шуму до зображення протягом багатьох кроків, поки воно не стане повністю невпізнаваним;
- Зворотний процес (видалення шуму): далі модель навчається зворотному процесу, поступово видаляючи шум крок за кроком, щоб відновити змістовне зображення;
- Навчання: дифузійні моделі навчаються передбачати та видаляти шум на кожному кроці, що дозволяє їм генерувати чіткі та якісні зображення з випадкового шуму.
Популярними прикладами є MidJourney, DALL-E та Stable Diffusion, які відомі створенням реалістичних і художніх зображень. Дифузійні моделі широко використовуються для AI-генерованого мистецтва, синтезу зображень високої роздільної здатності та креативного дизайну.
Приклади зображень, згенерованих дифузійними моделями
Реалістичне зображення баскетболіста з бородою у жовто-фіолетовій формі, який виконує данк і перемагає демонів у баскетбольній грі; вся дія відбувається в пеклі.
Сюрреалістична красива художня фотографія білого Volkswagen Golf GTI 1990 року на безкрайньому полі білих квітів у гармонії з природою, серед безмежних пагорбів, вкритих квітами; ботанічний стиль, природне освітлення, художній ефект, туман, фотореалістичний сюрреалізм, ультра деталізація, плівка Kodak, природне світло, ширококутний об'єктив, f 1.20
Картина бежевого пуделя, що лежить на зеленому дивані з зелено-білою смугастою подушкою у стилі Ферфілда Портера, абстрактний експресіонізм, з виразними мазками на бежевому тлі
Екстремальний крупний план шкіри жінки середземноморського або латиноамериканського походження, що підкреслює комбінований тип шкіри з помітною жирністю на лобі та носі, тоді як щоки виглядають сухішими та злегка лущаться. Пори більш помітні в Т-зоні, а природний блиск відображає вироблення шкірного сала. Шкіра має поєднання теплих і золотистих підтонов, з нерівномірною текстурою через різний рівень зволоження. М'яке природне освітлення підкреслює реалістичний контраст між сухими та жирними ділянками. Тло розмите, акцент зосереджено на її кольорі обличчя.
Виклики та етичні питання
Попри те, що зображення, створені штучним інтелектом, вражають, вони мають виклики:
- Відсутність контролю: ШІ не завжди генерує саме те, що потрібно користувачу;
- Обчислювальні ресурси: створення якісних зображень за допомогою ШІ потребує дорогого та потужного обладнання;
- Упередженість моделей ШІ: оскільки ШІ навчається на існуючих зображеннях, він може повторювати упередження, що містяться в даних.
Існують також етичні питання:
- Кому належить мистецтво ШІ?: якщо ШІ створює твір мистецтва, чи належить він людині, яка використала ШІ, чи компанії-розробнику?
- Фейкові зображення та дипфейки: GAN можуть використовуватися для створення фейкових зображень, що виглядають реалістично, що може призводити до дезінформації та проблем із приватністю.
Сучасне використання генерації зображень ШІ
Зображення, створені штучним інтелектом, вже мають значний вплив у різних галузях:
- Індустрія розваг: відеоігри, кіно та анімація використовують ШІ для створення фону, персонажів і спецефектів;
- Мода: дизайнери застосовують ШІ для створення нових стилів одягу, а онлайн-магазини — для віртуальних примірок;
- Графічний дизайн: ШІ допомагає художникам і дизайнерам швидко створювати логотипи, постери та маркетингові матеріали.
Майбутнє генерації зображень за допомогою ШІ
Оскільки генерація зображень за допомогою ШІ постійно вдосконалюється, вона продовжить змінювати способи створення та використання зображень. У мистецтві, бізнесі чи розвагах ШІ відкриває нові можливості та робить творчу роботу простішою й захопливішою.
Дякуємо за ваш відгук!
