Трансферне навчання у комп'ютерному зорі
Свайпніть щоб показати меню
Трансферне навчання дозволяє повторно використовувати моделі, навчені на великих наборах даних, для нових завдань з обмеженою кількістю даних. Замість створення нейронної мережі з нуля, використовується попередньо навчена модель для підвищення ефективності та продуктивності. Протягом цього курсу ви вже зустрічали подібні підходи в попередніх розділах, які заклали основу для ефективного застосування трансферного навчання.
Що таке трансферне навчання?
Трансферне навчання — це техніка, за якої модель, навчена для одного завдання, адаптується до іншого, спорідненого завдання. У комп'ютерному зорі моделі, попередньо навчені на великих наборах даних, таких як ImageNet, можуть бути донавчені для конкретних застосувань, наприклад, у медичній візуалізації або автономному водінні.
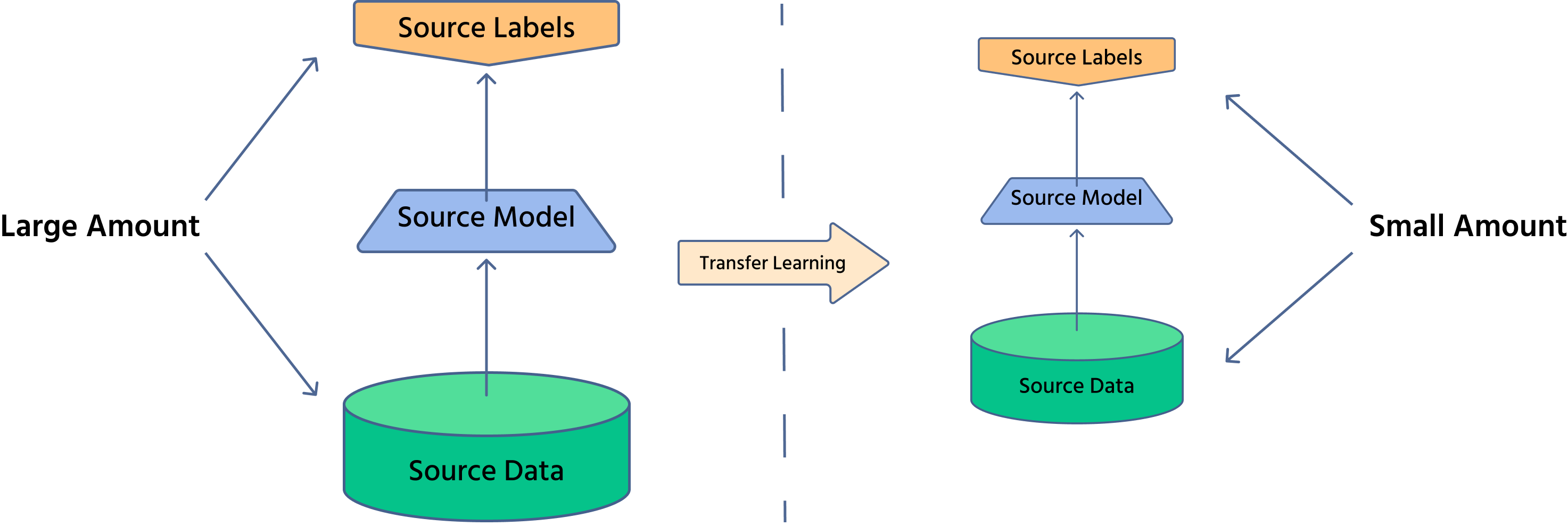
Чому трансферне навчання є важливим?
- Зменшення часу навчання: оскільки модель вже навчилася загальним ознакам, потрібні лише незначні коригування;
- Менша потреба у даних: корисно у випадках, коли отримання розмічених даних є дорогим;
- Підвищення продуктивності: попередньо навчені моделі забезпечують надійне вилучення ознак, що покращує точність.
Робочий процес трансферного навчання
Типовий робочий процес трансферного навчання включає кілька ключових етапів:
-
Вибір попередньо натренованої моделі:
- Вибір моделі, навченої на великому наборі даних (наприклад, ResNet, VGG, YOLO);
- Такі моделі вже навчилися корисним представленням, які можна адаптувати для нових завдань.
-
Модифікація попередньо натренованої моделі:
- Виділення ознак: заморожування ранніх шарів і перенавчання лише пізніх шарів для нової задачі;
- Тонке налаштування: розморожування деяких або всіх шарів і перенавчання їх на новому наборі даних.
-
Навчання на новому наборі даних:
- Навчання модифікованої моделі з використанням меншого набору даних, специфічного для цільової задачі;
- Оптимізація за допомогою таких технік, як зворотне поширення помилки та функції втрат.
-
Оцінювання та ітерація:
- Оцінка продуктивності за допомогою метрик, таких як точність, прецизійність, повнота та mAP;
- Додаткове тонке налаштування за потреби для покращення результатів.
Популярні попередньо натреновані моделі
Деякі з найбільш поширених попередньо натренованих моделей для комп'ютерного зору:
- ResNet: глибокі резидуальні мережі, які дозволяють навчати дуже глибокі архітектури;
- VGG: проста архітектура з однорідними згортковими шарами;
- EfficientNet: оптимізована для високої точності з меншою кількістю параметрів;
- YOLO: передова (SOTA) модель для розпізнавання об'єктів у реальному часі.
Тонке налаштування проти вилучення ознак
Вилучення ознак передбачає використання шарів попередньо навченої моделі як фіксованих витягувачів ознак. У цьому підході фінальний шар класифікації оригінальної моделі зазвичай видаляється та замінюється новим, специфічним для цільового завдання. Попередньо навчені шари залишаються замороженими, тобто їхні ваги не оновлюються під час навчання, що пришвидшує навчання та потребує меншої кількості даних.
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Flatten
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
for layer in base_model.layers:
layer.trainable = False # Freeze base model layers
x = Flatten()(base_model.output)
x = Dense(256, activation='relu')(x)
x = Dense(10, activation='softmax')(x) # Task-specific output
model = Model(inputs=base_model.input, outputs=x)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Тонке налаштування, навпаки, передбачає ще один крок — розморожування деяких або всіх попередньо навчених шарів і повторне їх навчання на новому наборі даних. Це дозволяє моделі краще адаптувати вивчені ознаки до специфічних характеристик нового завдання, що часто призводить до підвищення точності — особливо якщо новий набір даних є досить великим або суттєво відрізняється від початкових даних для навчання.
for layer in base_model.layers[-10:]: # Unfreeze last 10 layers
layer.trainable = True
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Застосування трансферного навчання
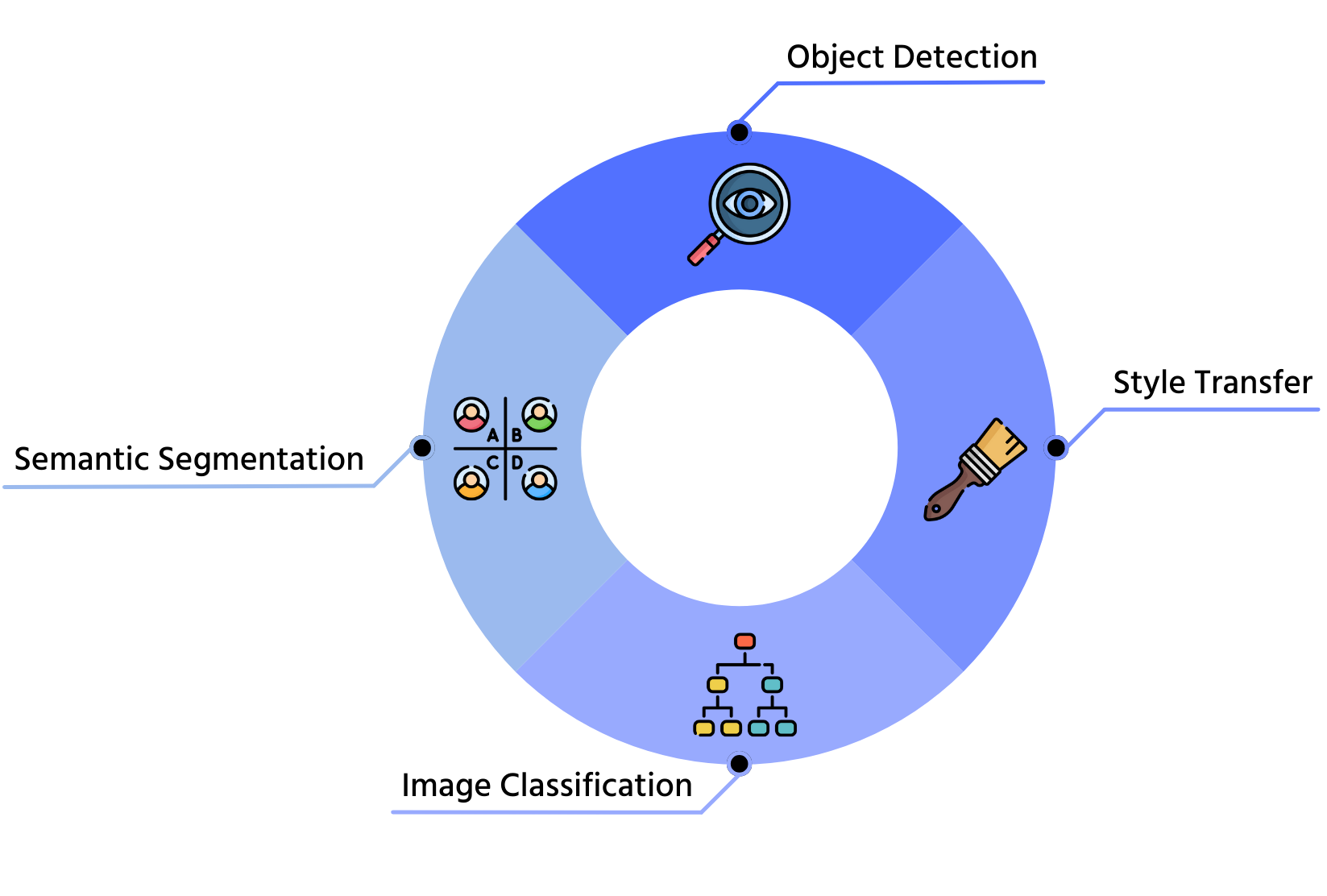
1. Класифікація зображень
Класифікація зображень полягає у призначенні міток зображенням на основі їхнього візуального вмісту. Попередньо навчені моделі, такі як ResNet та EfficientNet, можна адаптувати для конкретних завдань, наприклад, медичної візуалізації або класифікації дикої природи.
Приклад:
- Вибір попередньо натренованої моделі (наприклад, ResNet);
- Модифікація шару класифікації відповідно до цільових класів;
- Дотонке налаштування з меншою швидкістю навчання.
2. Детекція об'єктів
Детекція об'єктів включає як ідентифікацію об'єктів, так і їх локалізацію на зображенні. Трансферне навчання дозволяє моделям, таким як Faster R-CNN, SSD та YOLO, ефективно знаходити конкретні об'єкти на нових наборах даних.
Приклад:
- Використання попередньо натренованої моделі для детекції об'єктів (наприклад, YOLOv8);
- Дотонке налаштування на власному наборі даних із новими класами об'єктів;
- Оцінка продуктивності та оптимізація за потреби.
3. Семантична сегментація
Семантична сегментація класифікує кожен піксель зображення у визначені категорії. Моделі, такі як U-Net та DeepLab, широко використовуються у сферах автономного водіння та медичної візуалізації.
Приклад:
- Використання попередньо натренованої моделі сегментації (наприклад, U-Net);
- Навчання на галузевому наборі даних;
- Налаштування гіперпараметрів для підвищення точності.
4. Стильове перенесення
Стильове перенесення застосовує візуальний стиль одного зображення до іншого, зберігаючи його оригінальний вміст. Ця техніка часто використовується у цифровому мистецтві та покращенні зображень, із застосуванням попередньо навчених моделей, таких як VGG.
Приклад:
- Вибір моделі для стильового перенесення (наприклад, VGG);
- Введення зображень вмісту та стилю;
- Оптимізація для отримання візуально привабливих результатів.
1. Яка основна перевага використання трансферного навчання у комп'ютерному зорі?
2. Який підхід використовується у трансферному навчанні, коли змінюється лише останній шар попередньо навченої моделі, а попередні шари залишаються незмінними?
3. Яка з наведених моделей зазвичай використовується для трансферного навчання в задачах детекції об'єктів?
Дякуємо за ваш відгук!
Запитати АІ
Запитати АІ

Запитайте про що завгодно або спробуйте одне із запропонованих запитань, щоб почати наш чат
