Якірні блоки
Свайпніть щоб показати меню
Якірний бокс — це заздалегідь визначена обмежувальна рамка з фіксованим розміром і співвідношенням сторін, розміщена у певних позиціях по всьому зображенню.
Чому використовують якірні бокси в задачах детекції об'єктів
Якірні бокси — це базове поняття в сучасних моделях детекції об'єктів, таких як Faster R-CNN та YOLO. Вони слугують заздалегідь визначеними еталонними рамками, які допомагають знаходити об'єкти різних розмірів і співвідношень сторін, що робить детекцію швидшою та надійнішою.
Замість того, щоб знаходити об'єкти з нуля, моделі використовують якірні бокси як початкові точки, коригуючи їх для кращого співпадіння з виявленими об'єктами. Такий підхід підвищує ефективність і точність, особливо при роботі з об'єктами різних масштабів.
Різниця між якірним боксом і обмежувальною рамкою
- Якірний бокс: заздалегідь визначений шаблон, який використовується як еталон під час детекції об'єктів;
- Обмежувальна рамка: фінальна передбачена рамка після коригування якірного боксу для відповідності реальному об'єкту.

На відміну від обмежувальних рамок, які динамічно коригуються під час прогнозування, anchor boxes фіксуються у визначених позиціях до початку виявлення об'єктів. Моделі навчаються уточнювати anchor boxes шляхом зміни їх розміру, положення та співвідношення сторін, у підсумку перетворюючи їх на фінальні обмежувальні рамки, що точно відображають знайдені об'єкти.
Як мережа генерує anchor boxes
Anchor boxes застосовуються не безпосередньо до зображення, а до карт ознак, отриманих із зображення. Після виділення ознак набір anchor boxes розміщується на цих картах ознак, змінюючись за розміром і співвідношенням сторін. Вибір форм anchor boxes є критичним і передбачає баланс між виявленням малих і великих об'єктів.
Для визначення розмірів anchor boxes моделі зазвичай використовують поєднання ручного вибору та кластеризаційних алгоритмів, таких як K-Means, для аналізу набору даних і визначення найпоширеніших форм і розмірів об'єктів. Ці попередньо визначені anchor boxes потім застосовуються у різних місцях на картах ознак. Наприклад, модель для виявлення об'єктів може використовувати anchor boxes розмірів (16x16), (32x32), (64x64) із співвідношеннями сторін 1:1, 1:2, and 2:1.
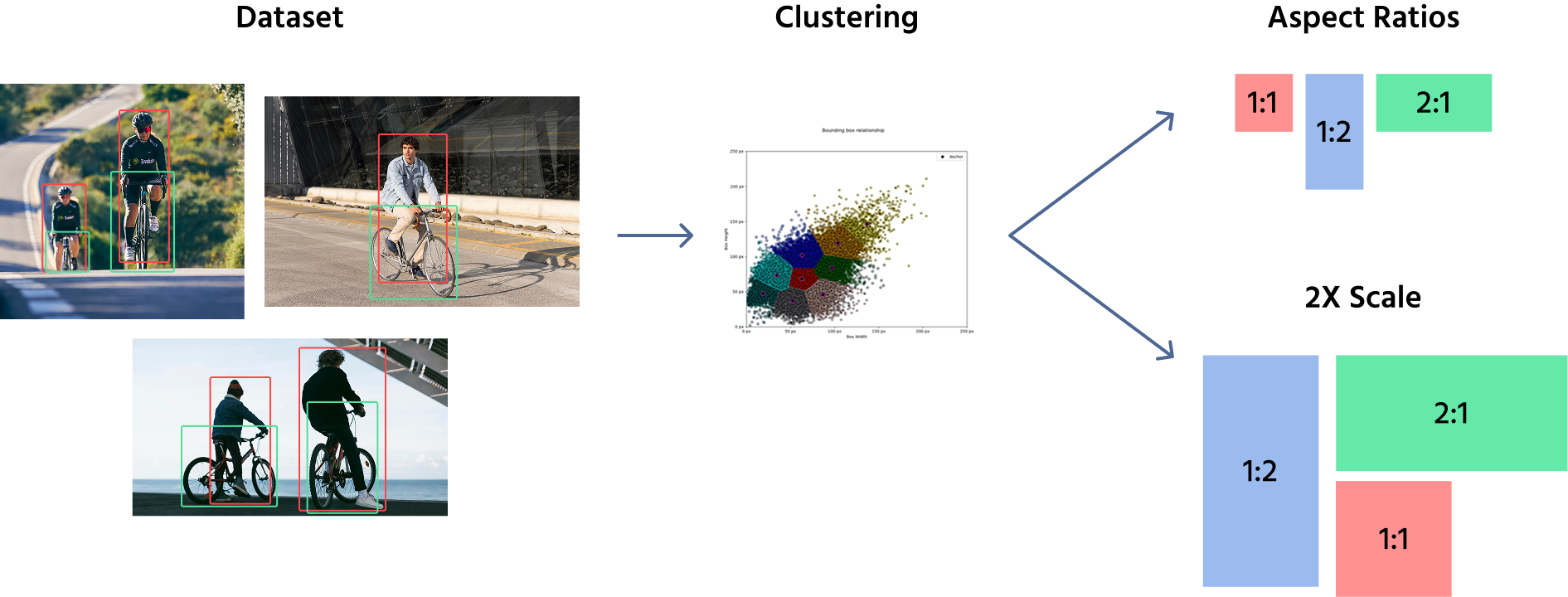
Після визначення цих anchor boxes вони застосовуються до карт ознак, а не до оригінального зображення. Модель призначає кілька anchor boxes кожній позиції на карті ознак, охоплюючи різні форми та розміри. Під час навчання мережа коригує anchor boxes, прогнозуючи зсуви, уточнюючи їхній розмір і положення для кращого відображення об'єктів.
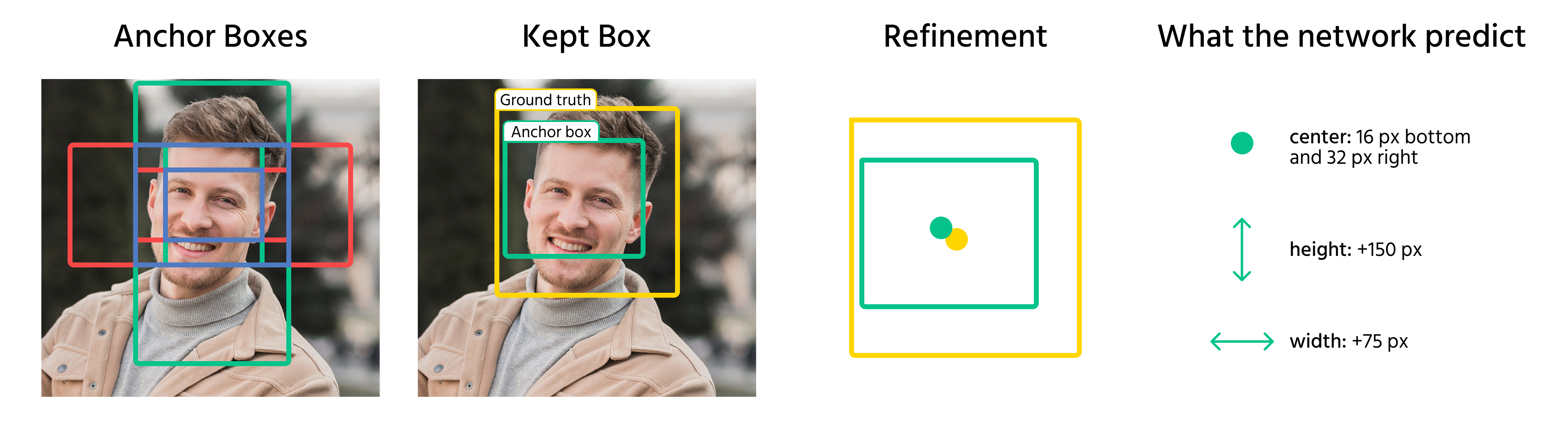
Від anchor box до bounding box
Після призначення anchor boxes об'єктам модель прогнозує зсуви для їх уточнення. Ці зсуви включають:
- Коригування координат центру box;
- Масштабування ширини та висоти;
- Зміщення box для кращого вирівнювання з об'єктом.
Застосовуючи ці перетворення, модель перетворює anchor boxes у фінальні bounding boxes, які максимально точно відповідають об'єктам на зображенні.
Підходи без використання або зі зменшеною кількістю anchor-боксів
Хоча anchor-бокси широко застосовуються, деякі моделі прагнуть зменшити залежність від них або повністю їх усунути:
- Anchor-free методи: моделі, такі як
CenterNetіFCOS, визначають розташування об'єктів без попередньо заданих anchor-боксів, що знижує складність; - Підходи зі зменшеною кількістю anchor-боксів:
EfficientDetіYOLOv4оптимізують кількість anchor-боксів, забезпечуючи баланс між швидкістю виявлення та точністю.
Ці підходи спрямовані на підвищення ефективності виявлення об'єктів при збереженні високої продуктивності, особливо для задач реального часу.
Підсумовуючи, anchor-бокси є важливою складовою детекції об'єктів, допомагаючи моделям ефективно знаходити об'єкти різних розмірів і пропорцій. Проте нові досягнення досліджують способи зменшення або повного усунення anchor-боксів для ще швидшої та гнучкішої детекції.
1. Яка основна роль anchor boxes у задачі детекції об'єктів?
2. Чим anchor boxes відрізняються від bounding boxes?
3. Який метод зазвичай використовується для визначення оптимальних розмірів anchor boxes?
Дякуємо за ваш відгук!
Запитати АІ
Запитати АІ

Запитайте про що завгодно або спробуйте одне із запропонованих запитань, щоб почати наш чат
Якірні блоки
Якірний бокс — це заздалегідь визначена обмежувальна рамка з фіксованим розміром і співвідношенням сторін, розміщена у певних позиціях по всьому зображенню.
Чому використовують якірні бокси в задачах детекції об'єктів
Якірні бокси — це базове поняття в сучасних моделях детекції об'єктів, таких як Faster R-CNN та YOLO. Вони слугують заздалегідь визначеними еталонними рамками, які допомагають знаходити об'єкти різних розмірів і співвідношень сторін, що робить детекцію швидшою та надійнішою.
Замість того, щоб знаходити об'єкти з нуля, моделі використовують якірні бокси як початкові точки, коригуючи їх для кращого співпадіння з виявленими об'єктами. Такий підхід підвищує ефективність і точність, особливо при роботі з об'єктами різних масштабів.
Різниця між якірним боксом і обмежувальною рамкою
- Якірний бокс: заздалегідь визначений шаблон, який використовується як еталон під час детекції об'єктів;
- Обмежувальна рамка: фінальна передбачена рамка після коригування якірного боксу для відповідності реальному об'єкту.
На відміну від обмежувальних рамок, які динамічно коригуються під час прогнозування, anchor boxes фіксуються у визначених позиціях до початку виявлення об'єктів. Моделі навчаються уточнювати anchor boxes шляхом зміни їх розміру, положення та співвідношення сторін, у підсумку перетворюючи їх на фінальні обмежувальні рамки, що точно відображають знайдені об'єкти.
Як мережа генерує anchor boxes
Anchor boxes застосовуються не безпосередньо до зображення, а до карт ознак, отриманих із зображення. Після виділення ознак набір anchor boxes розміщується на цих картах ознак, змінюючись за розміром і співвідношенням сторін. Вибір форм anchor boxes є критичним і передбачає баланс між виявленням малих і великих об'єктів.
Для визначення розмірів anchor boxes моделі зазвичай використовують поєднання ручного вибору та кластеризаційних алгоритмів, таких як K-Means, для аналізу набору даних і визначення найпоширеніших форм і розмірів об'єктів. Ці попередньо визначені anchor boxes потім застосовуються у різних місцях на картах ознак. Наприклад, модель для виявлення об'єктів може використовувати anchor boxes розмірів (16x16), (32x32), (64x64) із співвідношеннями сторін 1:1, 1:2, and 2:1.
Після визначення цих anchor boxes вони застосовуються до карт ознак, а не до оригінального зображення. Модель призначає кілька anchor boxes кожній позиції на карті ознак, охоплюючи різні форми та розміри. Під час навчання мережа коригує anchor boxes, прогнозуючи зсуви, уточнюючи їхній розмір і положення для кращого відображення об'єктів.
Від anchor box до bounding box
Після призначення anchor boxes об'єктам модель прогнозує зсуви для їх уточнення. Ці зсуви включають:
- Коригування координат центру box;
- Масштабування ширини та висоти;
- Зміщення box для кращого вирівнювання з об'єктом.
Застосовуючи ці перетворення, модель перетворює anchor boxes у фінальні bounding boxes, які максимально точно відповідають об'єктам на зображенні.
Підходи без використання або зі зменшеною кількістю anchor-боксів
Хоча anchor-бокси широко застосовуються, деякі моделі прагнуть зменшити залежність від них або повністю їх усунути:
- Anchor-free методи: моделі, такі як
CenterNetіFCOS, визначають розташування об'єктів без попередньо заданих anchor-боксів, що знижує складність; - Підходи зі зменшеною кількістю anchor-боксів:
EfficientDetіYOLOv4оптимізують кількість anchor-боксів, забезпечуючи баланс між швидкістю виявлення та точністю.
Ці підходи спрямовані на підвищення ефективності виявлення об'єктів при збереженні високої продуктивності, особливо для задач реального часу.
Підсумовуючи, anchor-бокси є важливою складовою детекції об'єктів, допомагаючи моделям ефективно знаходити об'єкти різних розмірів і пропорцій. Проте нові досягнення досліджують способи зменшення або повного усунення anchor-боксів для ще швидшої та гнучкішої детекції.
Дякуємо за ваш відгук!
