Neural Network Implementation
Basic Neural Network Overview
You've now reached a stage where you're equipped with the essential knowledge of TensorFlow to create neural networks on your own. While most real-world neural networks are complex and typically built using high-level libraries like Keras, we'll construct a basic one using fundamental TensorFlow tools. This approach gives us hands-on experience with low-level tensor manipulation, helping us understand the underlying processes.
In earlier courses like Introduction to Neural Networks, you might recall the time and effort it took to build even a simple neural network, treating each neuron individually.

TensorFlow simplifies this process significantly. By leveraging tensors, you can encapsulate complex calculations, reducing the need for intricate coding. Our primary task is to set up a sequential pipeline of tensor operations.
Here's a brief refresher on the steps to get a neural network training process up and running:
Data Preparation and Model Creation
The initial phase of training a neural network involves preparing the data, encompassing both the inputs and outputs that the network will learn from. Additionally, the model's hyperparameters are established - these are the parameters that remain constant throughout the training process. The weights are initialized, typically drawn from a normal distribution, and the biases, which are often set to zero.
Forward Propagation
In forward propagation, each layer of the network typically follows these steps:
- Multiply the layer's input by its weights.
- Add a bias to the result.
- Apply an activation function to this sum.
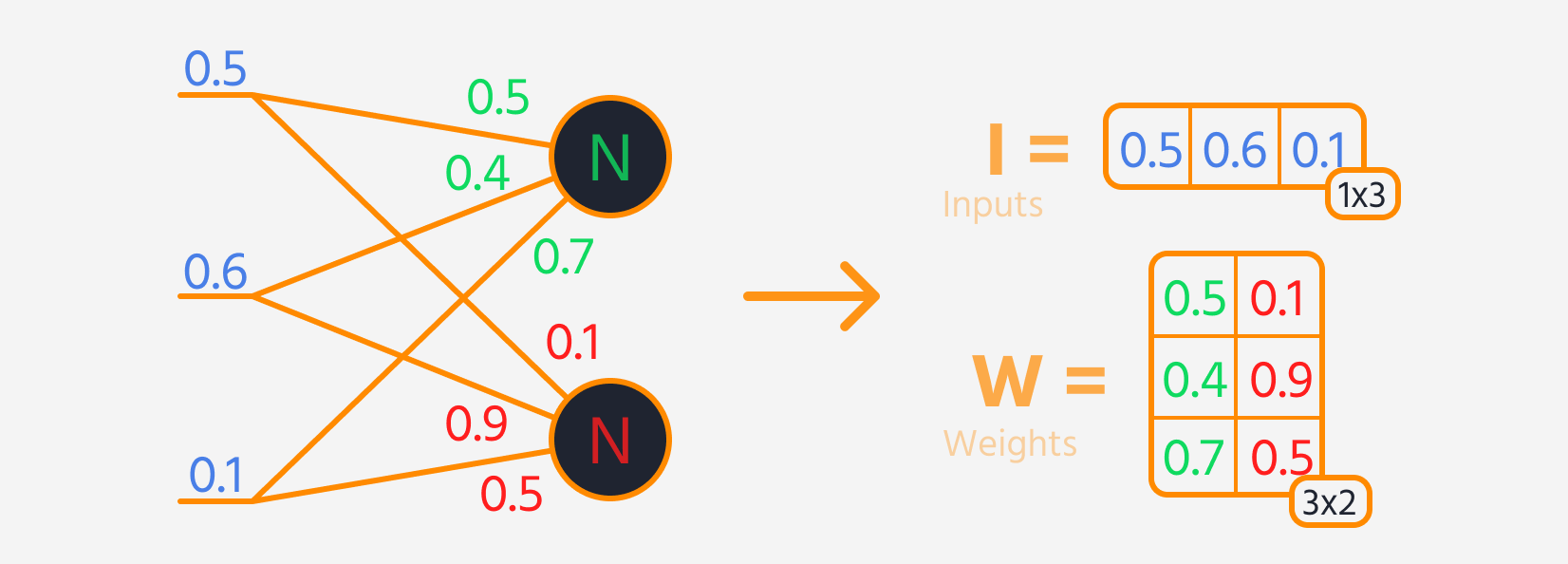
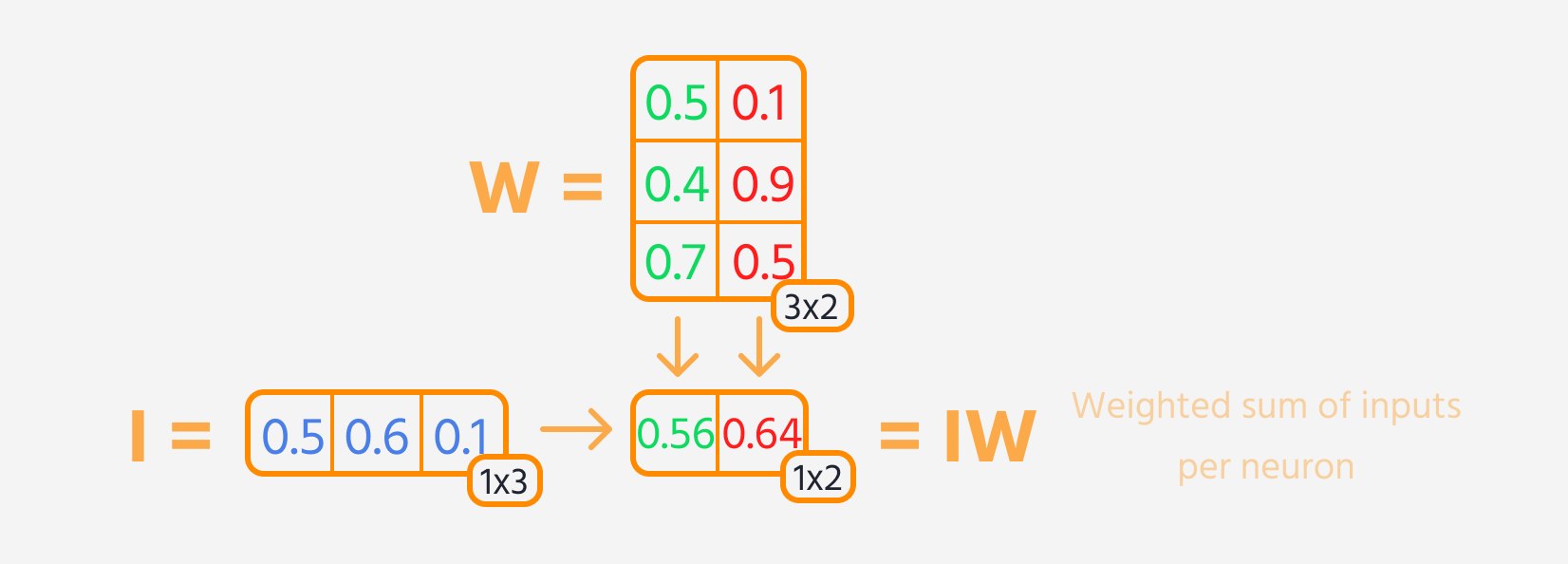
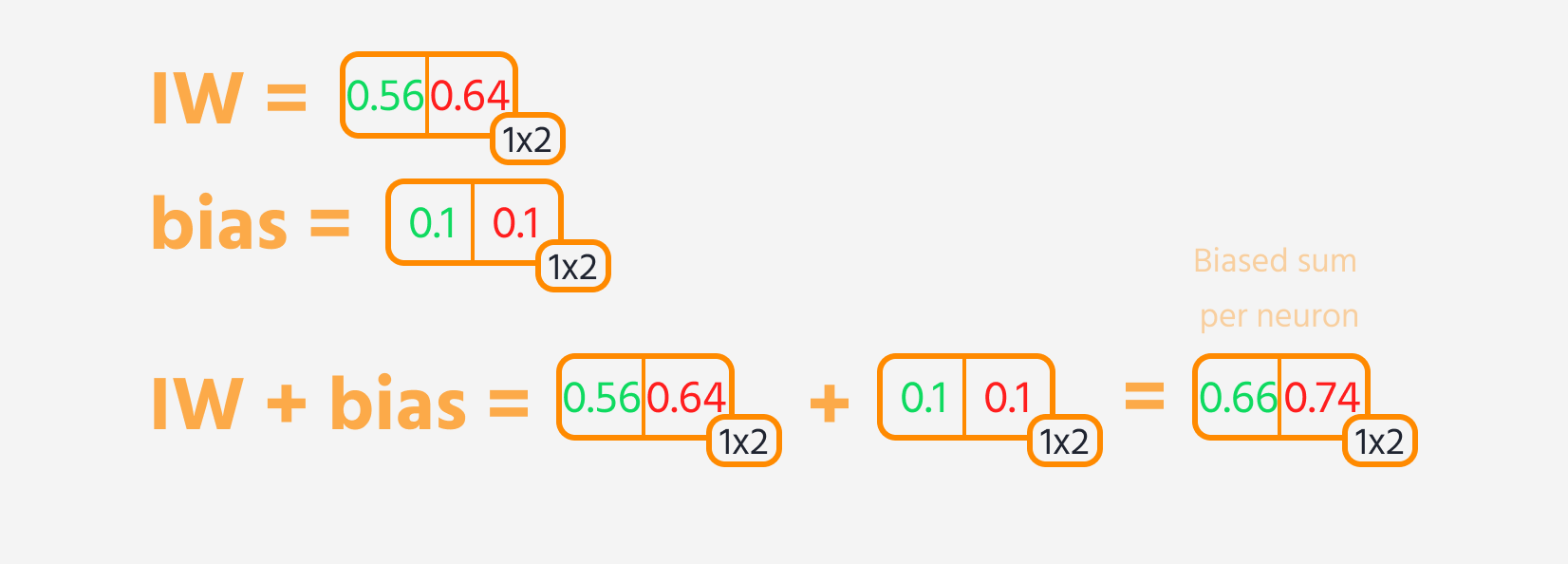


Then, loss can be calculated.
Backward Propagation
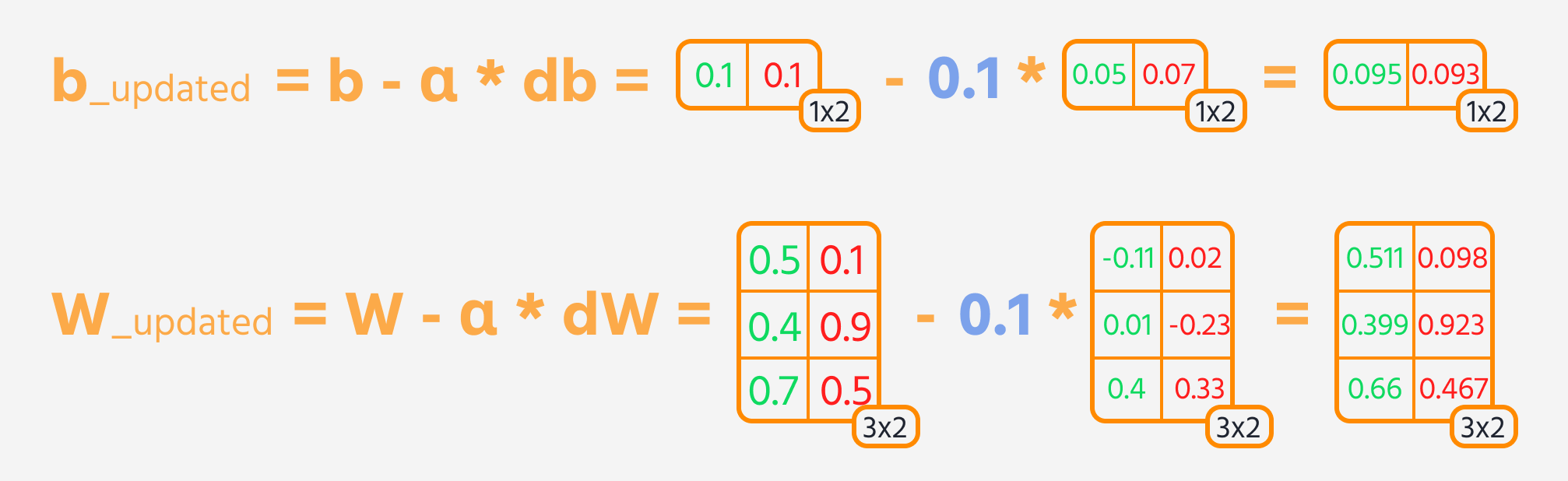
The next step is backward propagation, where we adjust the weights and biases based on their influence on the loss. This influence is represented by the gradient, which TensorFlow's Gradient Tape calculates automatically. We update the weights and biases by subtracting the gradient, scaled by the learning rate.
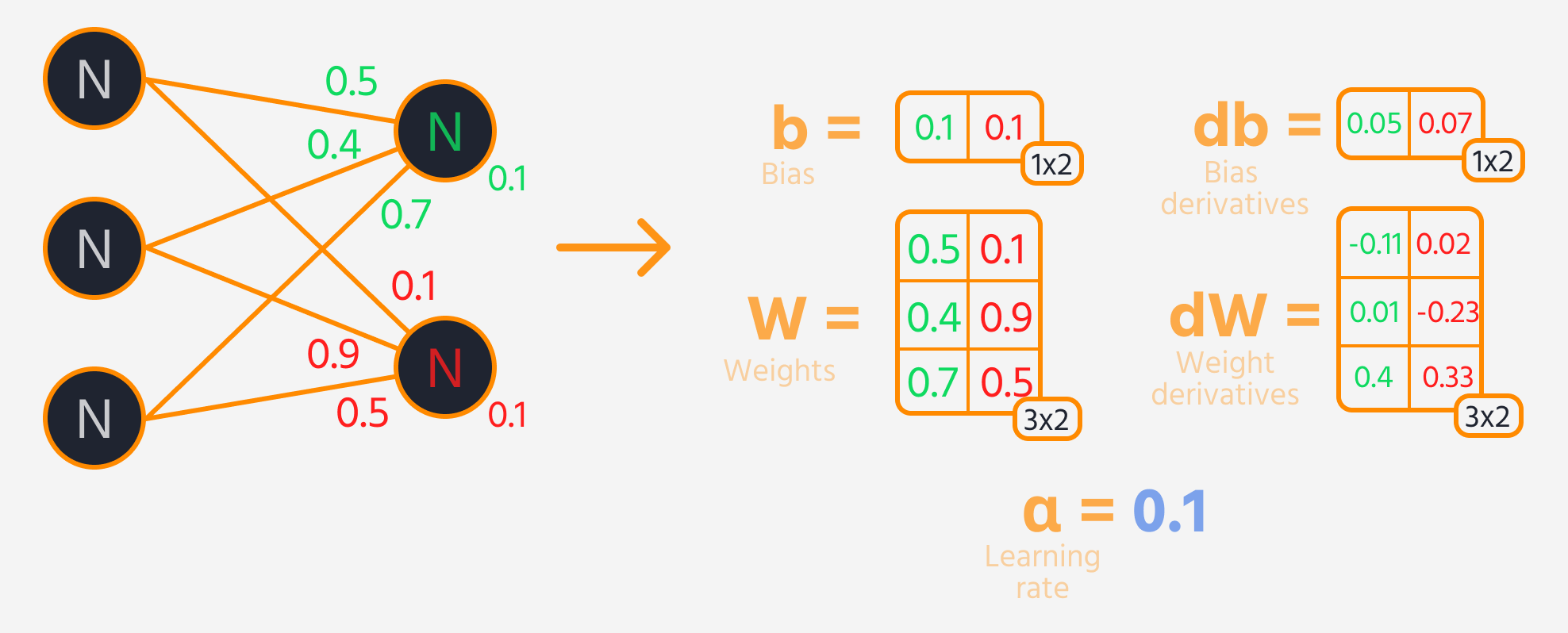
Training Loop
To effectively train the neural network, the training steps are repeated multiple times while tracking the model's performance. Ideally, the loss should decrease over epochs.
Thanks for your feedback!
single
Neural Network Implementation
Swipe to show menu
Basic Neural Network Overview
You've now reached a stage where you're equipped with the essential knowledge of TensorFlow to create neural networks on your own. While most real-world neural networks are complex and typically built using high-level libraries like Keras, we'll construct a basic one using fundamental TensorFlow tools. This approach gives us hands-on experience with low-level tensor manipulation, helping us understand the underlying processes.
In earlier courses like Introduction to Neural Networks, you might recall the time and effort it took to build even a simple neural network, treating each neuron individually.
TensorFlow simplifies this process significantly. By leveraging tensors, you can encapsulate complex calculations, reducing the need for intricate coding. Our primary task is to set up a sequential pipeline of tensor operations.
Here's a brief refresher on the steps to get a neural network training process up and running:
Data Preparation and Model Creation
The initial phase of training a neural network involves preparing the data, encompassing both the inputs and outputs that the network will learn from. Additionally, the model's hyperparameters are established - these are the parameters that remain constant throughout the training process. The weights are initialized, typically drawn from a normal distribution, and the biases, which are often set to zero.
Forward Propagation
In forward propagation, each layer of the network typically follows these steps:
- Multiply the layer's input by its weights.
- Add a bias to the result.
- Apply an activation function to this sum.
Then, loss can be calculated.
Backward Propagation
The next step is backward propagation, where we adjust the weights and biases based on their influence on the loss. This influence is represented by the gradient, which TensorFlow's Gradient Tape calculates automatically. We update the weights and biases by subtracting the gradient, scaled by the learning rate.
Training Loop
To effectively train the neural network, the training steps are repeated multiple times while tracking the model's performance. Ideally, the loss should decrease over epochs.
Swipe to start coding
Create a neural network designed to predict XOR operation outcomes. The network should consist of 2 input neurons, a hidden layer with 2 neurons, and 1 output neuron.
- Start by setting up the initial weights and biases. The weights should be initialized using a normal distribution, and biases should all be initialized to zero. Use the hyperparameters
input_size,hidden_size, andoutput_sizeto define the appropriate shapes for these tensors. - Utilize a function decorator to transform the
train_step()function into a TensorFlow graph. - Carry out forward propagation through both the hidden and output layers of the network. Use sigmoid activation function.
- Determine the gradients to understand how each weight and bias impacts the loss. Ensure the gradients are computed in the correct order, corresponding to the output variable names.
- Modify the weights and biases based on their respective gradients. Incorporate the
learning_ratein this adjustment process to control the extent of each update.
Solution
Data Preparation
X_data: this is the input data for the XOR function. It's a NumPy array of shape (4, 2), representing the four possible combinations of the XOR inputs (0,0), (0,1), (1,0), and (1,1);Y_data: this is the target output for each input combination inX_data. It's also a NumPy array but of shape (4, 1), representing the XOR output for each input pair.
Network Parameters
input_size: the size of the input layer, set to 2, corresponding to the two input nodes (for the two inputs of the XOR function);hidden_size: the size of the hidden layer, also set to 2. This choice is somewhat arbitrary but is enough to learn the XOR function;output_size: the size of the output layer, set to 1, corresponding to the single output node (the result of the XOR operation);learning_rate: this is the learning rate for the optimization algorithm, controlling how much the weights are adjusted during training.
Weights and Biases
W1andb1: the weights (W1) and biases (b1) for the connections from the input layer to the hidden layer.W1is a TensorFlow variable initialized with random values and has a shape of(input_size, hidden_size), i.e.,(2, 2).b1is a TensorFlow variable initialized with zeros and has a shape of(hidden_size), i.e.,(2);W2andb2: the weights (W2) and biases (b2) for the connections from the hidden layer to the output layer.W2is initialized with random values and has a shape of(hidden_size, output_size), i.e.,(2, 1).b2is initialized with zeros and has a shape of(output_size), i.e.,(1).
Training Function
train_step(): this is the core training function. It usestf.GradientTape()for automatic differentiation. In the forward pass, it computes the hidden layer activations (a1) and the output predictions (Y_pred). The loss is calculated as the Mean Squared Error betweenY_predandY. The function then computes the gradients and updates the weights and biases;tf.sigmoid(): a sigmoid activation function is used, which transforms the input into a value between0and1. This is used for both the hidden layer and the output layer.
Training Loop
- The network is trained for
2500epochs. In each epoch, thetrain_step()function is called, and the weights are updated. The loss is printed every500epochs to monitor the training progress.
Conclusion
Since the XOR function is a relatively straightforward task, we don't need advanced techniques like hyperparameter tuning, dataset splitting, or building complex data pipelines at this stage. This exercise is just a step towards building more sophisticated neural networks for real-world applications.
Mastering these basics is crucial before diving into advanced neural network construction techniques in upcoming courses, where we'll use the Keras library and explore methods to enhance model quality with TensorFlow's rich features.
Thanks for your feedback!
single
Ask AI
Ask AI

Ask anything or try one of the suggested questions to begin our chat
