Implementing Word2Vec
Swipe to show menu
Having understood how Word2Vec works, let's proceed to implement it using Python. The Gensim library, a robust open-source tool for natural language processing, provides a straightforward implementation through its Word2Vec class in gensim.models.
Preparing the Data
Word2Vec requires the text data to be tokenized, i.e., broken down into a list of lists where each inner list contains words from a specific sentence. For this example, we will use the novel Emma by English author Jane Austen as our corpus. We'll load a CSV file containing preprocessed sentences and then split each sentence into words:
12345678import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') # Split each sentence into words sentences = emma_df['Sentence'].str.split() # Print the fourth sentence (list of words) print(sentences[3])
emma_df['Sentence'].str.split() applies the .split() method to each sentence in the 'Sentence' column, resulting in a list of words for each sentence. Since the sentences were already preprocessed, with words separated by whitespaces, the .split() method is sufficient for this tokenization.
Training the Word2Vec Model
Now, let's focus on training the Word2Vec model using the tokenized data. The Word2Vec class offers a variety of parameters for customization. However, you will most commonly deal with the following parameters:
vector_size(100 by default): the dimensionality or size of the word embeddings;window(5 by default): the context window size;min_count(5 by default): words occurring fewer than this number will be ignored;sg(0 by default): the model architecture to use (1 for Skip-gram, 0 for CBoW).cbow_mean(1 by default): specifies whether the CBoW input context is summed (0) or averaged (1)
Speaking of the model architectures, CBoW is suited for larger datasets and scenarios where computational efficiency is crucial. Skip-gram, on the other hand, is preferable for tasks that require detailed understanding of word contexts, particularly effective in smaller datasets or when dealing with rare words.
12345678from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() # Initialize the model model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0)
Here, we set the embedding size to 200, the context window size to 5, and included all words by setting min_count=1. By setting sg=0, we chose to use the CBoW model.
Choosing the right embedding size and context window requires trade-offs. Larger embeddings capture more meaning but increase computational cost and risk overfitting. Smaller context windows are better at capturing syntax, while larger ones are better at capturing semantics.
Finding Similar Words
Once words are represented as vectors, we can compare them to measure similarity. While using distance is an option, the direction of a vector often carries more semantic meaning than its magnitude, especially in word embeddings.
However, using an angle as a similarity metric directly isn't that convenient. Instead, we can use the cosine of the angle between two vectors, also known as cosine similarity. It ranges from -1 to 1, with higher values indicating stronger similarity. This approach focuses on how aligned the vectors are, regardless of their length, making it ideal for comparing word meanings. Here's an illustration:
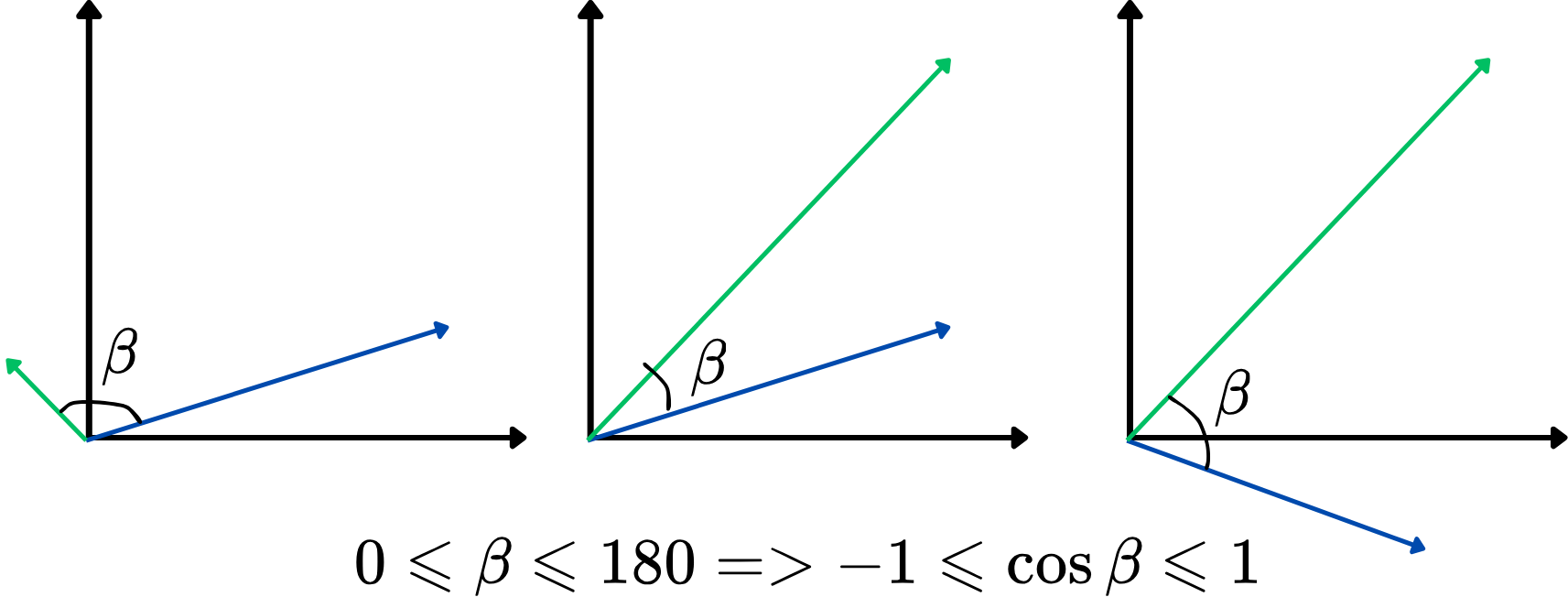
The higher the cosine similarity, the more similar the two vectors are, and vice versa. For example, if two word vectors have a cosine similarity close to 1 (the angle close to 0 degrees), it indicates that they are closely related or similar in context within the vector space.
Let's now find the top-5 most similar word to the word "man" using cosine similarity:
12345678910from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0) # Retrieve the top-5 most similar words to 'man' similar_words = model.wv.most_similar('man', topn=5) print(similar_words)
model.wv accesses the word vectors of the trained model, while the .most_similar() method finds the words whose embeddings are closest to the embedding of the specified word, based on cosine similarity. The topn parameter determines the number of top-N similar words to return.
Thanks for your feedback!
Ask AI
Ask AI

Ask anything or try one of the suggested questions to begin our chat
