Cursos relacionados
Ver Todos os CursosAvançado
Transformers Theory Essentials
A comprehensive, code-free exploration of transformer-based language models, focusing on their architecture, text generation mechanics, and the theoretical principles underlying their behavior.
Avançado
Introduction to Neural Networks with Python
Neural networks are powerful algorithms inspired by the structure of the human brain that are used to solve complex machine learning problems. You will build your own Neural Network from scratch to understand how it works. After this course, you will be able to create neural networks for solving classification and regression problems using the scikit-learn library.
Intermediário
Recurrent Neural Networks with Python
Master Recurrent neural networks and their advanced variants like LSTMs and GRUs using PyTorch. Gain hands-on experience processing sequential data for practical applications. Apply these powerful models to tackle real-world challenges in time series forecasting and various Natural language processing tasks.
The Architecture Of Liquid Neural Networks
How Brain Inspired AI Adapts In Real Time After Training
by Arsenii Drobotenko
Data Scientist, Ml Engineer
Mar, 2026・
6 min read

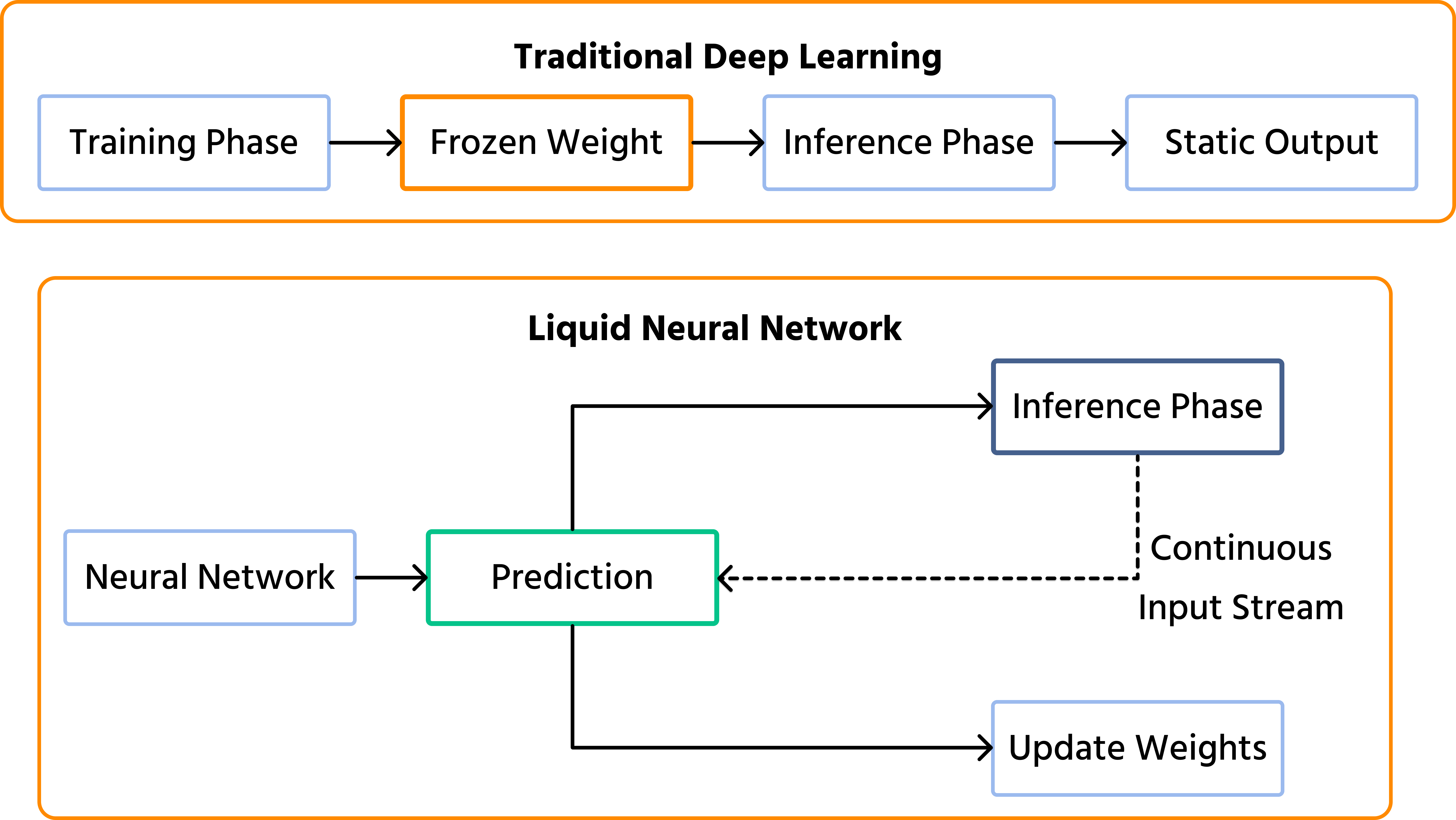
Modern deep learning models, including massive Large Language Models (LLMs), share one fundamental limitation: they are frozen in time. Once a standard neural network finishes its training phase, its internal weights are locked. If you deploy an autonomous drone trained in a bright, sunny environment and it suddenly flies into a heavy rainstorm, its frozen "brain" cannot adapt to the new visual noise. It can only react based on what it learned in the past.
To solve this, researchers at MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL) developed a radical new architecture: Liquid Neural Networks (LNNs). Inspired by the microscopic brain of the C. elegans worm, LNNs possess "fluid" parameters that dynamically change their equations on the fly, allowing the AI to learn and adapt during the inference phase.
The Problem With Frozen Weights
Standard artificial neural networks function like highly complex calculators. During training, they adjust millions or billions of parameters (weights and biases) to minimize errors. Once training is complete, these parameters are hardcoded.
In static environments – like classifying medical images or translating text—frozen weights are perfectly fine. However, in the real world, physics and environments are highly dynamic.
- Domain shift: when real-world conditions diverge from training data (e.g., a self-driving car encountering a snowstorm);
- Computational overhead: to handle unpredictable scenarios, traditional models must be trained on astronomically large datasets, resulting in bloated architectures that require massive GPUs to run.
What Are Liquid Neural Networks
Liquid Neural Networks are a specific class of continuous-time Recurrent Neural Networks (RNNs). Instead of just passing data through a static matrix of weights, the nodes in an LNN process data using non-linear differential equations.
The defining feature of an LNN is its dynamic time-constant. The network's hidden states (its "memory" and decision-making logic) are not fixed. The equations themselves change depending on the continuous stream of inputs they receive. If the environment becomes chaotic, the "liquid" network alters its internal wiring in real-time to focus on the most critical incoming signals, discarding the noise.
Run Code from Your Browser - No Installation Required

Why Smaller Is Actually Better
One of the most shocking aspects of LNNs is their size. While modern LLMs boast hundreds of billions of parameters, an LNN can achieve state-of-the-art performance in autonomous navigation with just tens of thousands of parameters.
Because the network doesn't need to memorize every possible edge case during training (since it can adapt later), it can remain incredibly lean. This compactness leads to high interpretability. Unlike "black box" LLMs, researchers can map out the exact decision-making pathways of an LNN, much like biologists map the 302 neurons of the C. elegans worm that inspired it.
| Feature | Traditional Deep Learning | Liquid Neural Networks (LNNs) |
|---|---|---|
| Post-Training State | Static (Frozen weights) | Dynamic (Equations adapt in real-time) |
| Parameter Count | Millions to Billions | Tens of Thousands |
| Compute Requirements | High (Requires heavy GPUs) | Ultra-Low (Can run on edge devices/Raspberry Pi) |
| Interpretability | Black Box | Highly Transparent |
Real World Applications
Because of their ability to process continuous streams of time-series data with very little computing power, LNNs are uniquely suited for "edge AI" (AI running directly on devices rather than in the cloud).
- Autonomous drones and robotics: MIT successfully deployed LNN-powered drones that navigated unfamiliar, dense forests flawlessly, outperforming traditional deep learning models that got confused by the novel environment;
- Autonomous driving: self-driving cars equipped with LNNs can adapt their steering and braking algorithms in real-time when a sudden rainstorm alters the friction of the road;
- High-frequency financial trading: processing highly volatile, continuous streams of market data where the underlying "rules" of the market shift rapidly;
- Medical monitoring: analyzing continuous, noisy ECG or EEG signals in real-time to predict sudden cardiac or neurological events.
Conclusions
Liquid Neural Networks challenge the "bigger is better" philosophy that has dominated AI for the last decade. By embedding continuous-time differential equations into the architecture, LNNs prove that a highly adaptable, compact brain can outperform a massive, rigid one in real-world scenarios. As we push towards ubiquitous robotics, edge computing, and autonomous systems operating in unpredictable environments, LNNs provide the vital blueprint for machines that don't just execute past training, but genuinely learn in the moment.
Start Learning Coding today and boost your Career Potential
FAQ
Q: Will LNNs replace models like ChatGPT?
A: No. LNNs are designed for continuous time-series data (like video frames, sensor readings, or audio streams) and edge computing. They are not optimized for processing massive, static datasets of text like Large Language Models are. They serve completely different engineering purposes.
Q: Do LNNs forget their original training when they adapt?
A: The core "laws" learned during training are preserved within the structure of the differential equations. The network doesn't "forget" the baseline; rather, the dynamic time-constants allow the network's sensitivity to inputs to flex and change, filtering out new noise without overwriting its foundational training.
Q: Why was a worm the inspiration for this advanced AI?
A: The C. elegans nematode has only 302 neurons, yet it can navigate, find food, and survive complex environments. MIT researchers realized that the worm's neurons do not act like simple binary switches (like standard artificial neurons). Instead, their synapses release continuous variables over time. By modeling this fluid, continuous interaction, they created an AI architecture that does more with drastically less.
Este artigo foi útil?
Compartilhar:
Este artigo foi útil?
Compartilhar:
Cursos relacionados
Ver Todos os CursosAvançado
Transformers Theory Essentials
A comprehensive, code-free exploration of transformer-based language models, focusing on their architecture, text generation mechanics, and the theoretical principles underlying their behavior.
Avançado
Introduction to Neural Networks with Python
Neural networks are powerful algorithms inspired by the structure of the human brain that are used to solve complex machine learning problems. You will build your own Neural Network from scratch to understand how it works. After this course, you will be able to create neural networks for solving classification and regression problems using the scikit-learn library.
Intermediário
Recurrent Neural Networks with Python
Master Recurrent neural networks and their advanced variants like LSTMs and GRUs using PyTorch. Gain hands-on experience processing sequential data for practical applications. Apply these powerful models to tackle real-world challenges in time series forecasting and various Natural language processing tasks.
Proving Bigger Isn't Always Better Using Small Language Models
How Compact Models Are Revolutionizing Privacy, Cost, and Edge Computing
by Arsenii Drobotenko
Data Scientist, Ml Engineer
Feb, 2026・7 min read

Automating AI Evaluation with LLM-as-a-Judge
Replacing Manual Review with Scalable AI Grading
by Arsenii Drobotenko
Data Scientist, Ml Engineer
Feb, 2026・5 min read

How the 1958 Perceptron Built ChatGPT
From Linear Classifiers to Large Language Models
by Radomanova Sofia
Data Analyst
May, 2026・6 min read

Conteúdo deste artigo
