Cursos relacionados
Ver Todos los CursosAvanzado
Transformers Theory Essentials
A comprehensive, code-free exploration of transformer-based language models, focusing on their architecture, text generation mechanics, and the theoretical principles underlying their behavior.
Intermedio
RAG Theory Essentials
A comprehensive, theory-focused course on the core concepts, architectures, and evaluation strategies behind Retrieval-Augmented Generation (RAG) systems. Designed for learners seeking a deep understanding of why RAG exists, how retrieval and generation are integrated, and how to evaluate and improve RAG pipelines.
RAG for Bridging the Gap Between AI and Your Data
How to Teach AI to Use Your Private Data Without Hallucinations
by Arsenii Drobotenko
Data Scientist, Ml Engineer
Feb, 2026・
10 min read

Imagine asking a powerful AI assistant for a summary of your company’s revenue report released this morning. The model generates a confident, fluent, and detailed response. There is just one problem: the numbers are entirely made up.
This phenomenon is known as "hallucination," and it stems from a fundamental limitation of traditional Large Language Models (LLMs). Models like GPT-4 or Llama 3 are frozen in time; they only know what they learned during training, which might have ended months or years ago. Asking them about current events or private internal data is like forcing a student to take a history exam on events that haven't happened yet.
Retrieval-Augmented Generation (RAG) is the architectural breakthrough that solves this. It transforms the AI from a closed system relying on memory into an open research assistant that can consult your private data, documents, and real-time information before answering.
Why One Brain Isn't Enough
In the corporate world, accuracy is not optional. A lawyer cannot use an AI that invents case law, and a doctor cannot rely on a model that hallucinates drug interactions.
Standard LLMs face two critical hurdles in business adoption:
- The knowledge cutoff: Retraining a massive model every time a new document is created is financially impossible;
- Data privacy: companies cannot simply feed sensitive financial records or user data into a public model's training set due to GDPR, security risks, and the inability to "delete" that data later.
RAG addresses these ethical and practical concerns by decoupling intelligence (the LLM) from knowledge (the data). The model acts as the reasoning engine, while the data remains stored securely in an external database, fully under the company's control.
How RAG Works
To understand RAG, we need to define three key components that work together:
- The LLM (the processor): this is the "brain" (e.g., ChatGPT, Claude). It understands instructions, grammar, and logic, but it doesn't know your specific data;
- Vector embeddings (the translator): computers don't understand text; they understand numbers. "Embeddings" are a technique where text is converted into long lists of numbers (vectors). Crucially, these numbers represent meaning. The sentence "The canine barked" will have a mathematical representation very close to "The dog made a noise," even though the words are different;
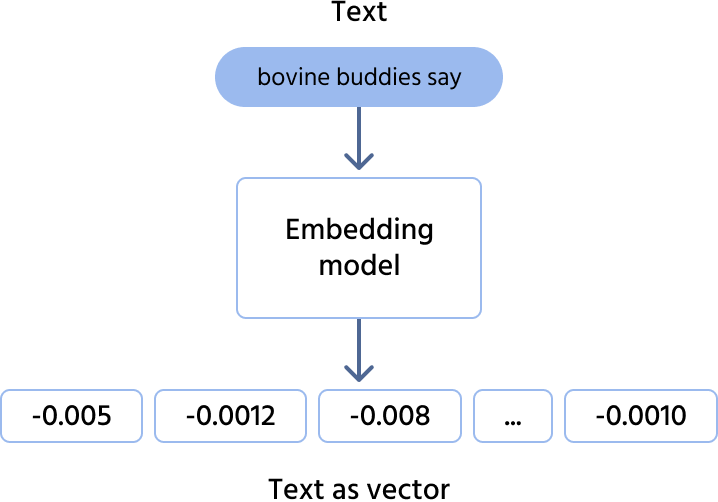
- Vector database (the library): a specialized database designed to store and quickly search these vectors based on semantic similarity rather than exact keyword matches.
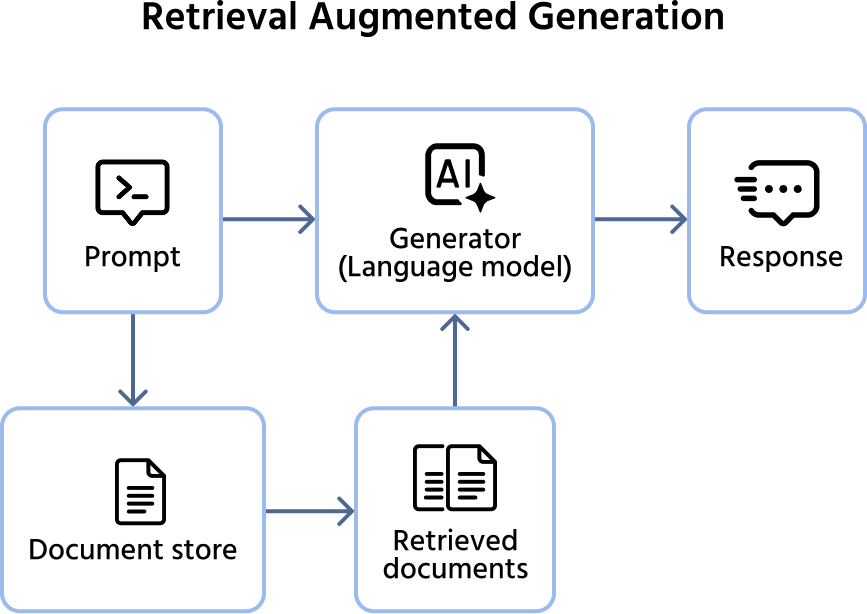
The RAG Architecture
The process follows a three-step pipeline: ingestion, retrieval, and generation.
- Ingestion: your documents (PDFs, wikis, emails) are split into small chunks, converted into vectors, and stored in the database;
- Retrieval: when a user asks a question, the system converts that question into a vector and searches the database for the most relevant chunks of text (context);
- Generation: the system combines the user's question and the retrieved chunks into a single prompt. It sends this to the LLM with the instruction: "Using only the provided context, answer the user's question".
RAG vs. Fine-Tuning
A common misconception among beginners is that to teach an AI new information, you must "fine-tune" (retrain) it. In most business cases, this is incorrect. Fine-tuning is for changing how a model speaks; RAG is for changing what it knows.
| Feature | Fine-Tuning | RAG (Retrieval-Augmented Generation) |
|---|---|---|
| Analogy | Studying for an exam (Memorization) | Taking an exam with an open textbook |
| Primary Goal | Adapt style, tone, or specific format | Access facts, specific data, or new info |
| Data Freshness | Outdated the moment training stops | Real-time (updates instantly) |
| Hallucinations | High risk (model may "invent" facts) | Low risk (grounded in retrieved text) |
| Cost | High (requires expensive GPU training) | Lower (requires database infrastructure) |
| Traceability | "Black box" (hard to cite sources) | Transparent (can cite specific documents) |
Real-World Use Cases
RAG is currently the industry standard for building intelligent applications across various domains:
- Corporate knowledge management: instead of searching through thousands of folders on SharePoint or Google Drive, employees can ask a chatbot: "What is the updated travel policy for international flights?" The system retrieves the specific PDF page and summarizes the answer;
- Legal contract review: law firms use RAG to query thousands of pages of case files to identify specific clauses, risks, or contradictions without reading every page manually;
- Customer support automation: instead of generic replies, a support bot retrieves the user's specific order history and the latest shipping policies to provide a personalized, accurate resolution.
Challenges for RAG Architectures
While RAG is powerful, it introduces complexity to the system architecture.
- Latency (speed): adding a retrieval step takes time. Searching a database, ranking results, and processing the extra text can add latency (0.5 to 2 seconds) to the response. Developers must balance the depth of the search with the user's need for speed;
- The "lost in the middle" phenomenon: LLMs have a limited "context window" (the amount of text they can process at once). If the retrieval system pulls too many documents, the model might get overwhelmed and ignore crucial information buried in the middle of the text;
- Garbage in, garbage out: the quality of the answer is 100% dependent on the quality of the retrieval. If the search step finds irrelevant documents, the LLM will either hallucinate or fail to answer. Optimizing the "search" part is often harder than optimizing the "generation" part.
Future Outlook
The field of RAG is evolving rapidly. We are currently seeing the rise of GraphRAG, which combines vector search with Knowledge Graphs. This allows the AI to understand deep relationships between entities (e.g., "Person A is the CEO of Company B which owns Product C") rather than just matching similar words.
Additionally, Agentic RAG is emerging, where AI agents autonomously decide when they need to search for information, verify their own answers, and rewrite queries if the initial search fails.
¿Fue útil este artículo?
Compartir:
¿Fue útil este artículo?
Compartir:
Cursos relacionados
Ver Todos los CursosAvanzado
Transformers Theory Essentials
A comprehensive, code-free exploration of transformer-based language models, focusing on their architecture, text generation mechanics, and the theoretical principles underlying their behavior.
Intermedio
RAG Theory Essentials
A comprehensive, theory-focused course on the core concepts, architectures, and evaluation strategies behind Retrieval-Augmented Generation (RAG) systems. Designed for learners seeking a deep understanding of why RAG exists, how retrieval and generation are integrated, and how to evaluate and improve RAG pipelines.
Proving Bigger Isn't Always Better Using Small Language Models
How Compact Models Are Revolutionizing Privacy, Cost, and Edge Computing
by Arsenii Drobotenko
Data Scientist, Ml Engineer
Feb, 2026・7 min read

Automating AI Evaluation with LLM-as-a-Judge
Replacing Manual Review with Scalable AI Grading
by Arsenii Drobotenko
Data Scientist, Ml Engineer
Feb, 2026・5 min read

Moving Beyond Text with World Models and Physical Reality
Why the Next Frontier of Intelligence Is Not Written in Tokens
by Arsenii Drobotenko
Data Scientist, Ml Engineer
Feb, 2026・6 min read
Contenido de este artículo
