Relaterte kurs
Se alle kursMiddelsnivå
Introduction to Machine Learning with Python
Machine learning is now used everywhere. Want to learn it yourself? This course is an introduction to the world of Machine learning for you to learn basic concepts, work with Scikit-learn – the most popular library for ML and build your first Machine Learning project. This course is intended for students with a basic knowledge of Python, Pandas, and Numpy.
Nybegynner
Data Preprocessing and Feature Engineering with Python
Learn practical techniques to clean, transform, and engineer data for machine learning using Python. This course covers essential preprocessing steps, feature creation, and hands-on challenges to prepare data for modeling.
Navigating Imbalanced Datasets In Classification Models
Strategies For Handling Rare Events In Machine Learning
by Arsenii Drobotenko
Data Scientist, Ml Engineer
Mar, 2026・
8 min read

One of the most common and dangerous traps for a junior Data Scientist is the illusion of a "perfect" model. Imagine you build an AI to detect fraudulent credit card transactions. You train your model, test it, and it achieves an astonishing 99% accuracy. You deploy it, but soon realize it is missing almost every single fraudulent transaction. What went wrong?
You have just become a victim of an imbalanced dataset. In the real world, data is rarely split perfectly 50/50. Fraudulent transactions, rare diseases, or manufacturing defects often make up less than 1% of the total data. If you don't handle this imbalance correctly, your machine learning model will simply learn to predict the majority class every single time, rendering it completely useless for finding the rare events you actually care about.
The Accuracy Paradox Why 99 Percent Is Sometimes Terrible
When a dataset is highly imbalanced (e.g., 99 normal transactions and 1 fraudulent transaction), a "dumb" model that predicts "Normal" for everything will automatically achieve 99% accuracy. It successfully predicted 99 out of 100 cases. However, its ability to detect fraud – the actual goal of the model – is 0%. This phenomenon is known as the Accuracy Paradox.
To evaluate models on imbalanced data, you must abandon standard accuracy and use metrics that focus on the minority class
- Precision: out of all the cases the model flagged as fraud, how many were actually fraud? (Focuses on minimizing false positives);
- Recall (sensitivity): out of all the actual fraud cases in the dataset, how many did the model successfully find? (Focuses on minimizing false negatives);
- F1-score: the harmonic mean of Precision and Recall, providing a single metric that balances both concerns.
Run Code from Your Browser - No Installation Required

Data Level Solutions Resampling Techniques
The most intuitive way to fix an imbalanced dataset is to balance the data before feeding it to the machine learning algorithm. This is called resampling, and it generally takes two forms: Undersampling and Oversampling.
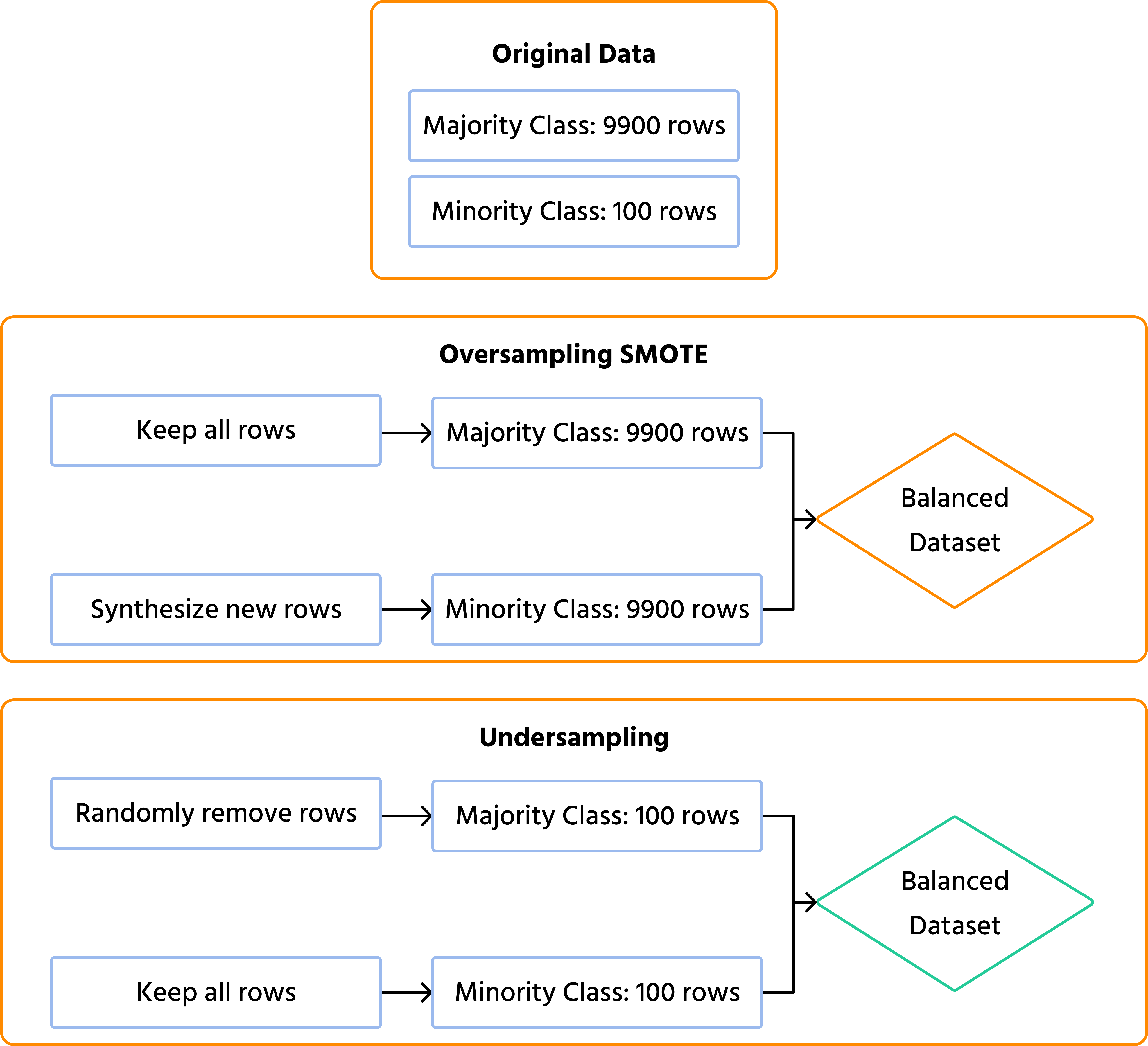
1. Random Undersampling
This technique involves randomly deleting examples from the majority class until it matches the size of the minority class.
- Math foundation: it applies a uniform probability distribution to the majority class , selecting a random subset . Every majority sample has an equal probability of being kept, ensuring the final subset size exactly equals the minority class size .
- Pros: it shrinks the dataset, making training much faster and less memory-intensive;
- Cons: you are literally throwing away valuable data. If your dataset is already small, undersampling might leave your model with too little information to learn complex patterns.
2. Oversampling and SMOTE
Instead of deleting data, oversampling increases the size of the minority class. While you can simply duplicate existing minority records, a much better approach is SMOTE (synthetic minority over-sampling technique).
SMOTE doesn't just copy data; it looks at the existing minority data points and uses K-Nearest Neighbors mathematics to generate entirely new, synthetic examples that blend in with the real ones.
- Math foundation: to create a new synthetic point, SMOTE selects a random minority point , finds its nearest minority neighbors, and randomly picks one neighbor . It then generates a new point along the line segment joining them using linear interpolation: , where is a random number between and .
Algorithm Level Solutions Class Weights
If you don't want to alter your dataset with resampling, you can modify the learning algorithm itself. Most modern machine learning implementations in Python (like Scikit-Learn's Random Forest, SVM, or Logistic Regression) include a class_weight parameter.
By setting class_weight='balanced', you fundamentally change the model's loss function.
- Math foundation: it automatically assigns a weight to each class inversely proportional to its frequency, using the formula: (where is the number of classes and is the number of samples in class ). The standard loss function for a given prediction is then multiplied by this weight ().
You tell the algorithm "If you make a mistake on the majority class, it's a minor penalty. But if you miss the minority class, the penalty is multiplied by ." This forces the algorithm to pay strict attention to the rare events during gradient descent training, even though they appear infrequently in the data.
| Technique | How It Works | Best Used When |
|---|---|---|
| Undersampling | Reduces majority class to match minority. | You have tens of millions of rows and strict memory limits. |
| SMOTE (Oversampling) | Creates synthetic examples of the minority class. | You have a smaller dataset and need the model to learn deep patterns. |
| Class Weights | Heavily penalizes errors made on the minority class. | You want a pure, computationally efficient solution without altering original data. |
Start Learning Coding today and boost your Career Potential
Conclusions
Handling imbalanced datasets is the dividing line between theoretical data science and real-world engineering. Rare events are often the most critical ones – whether it is identifying a fraudulent transaction, predicting machine failure, or diagnosing a rare illness. By understanding the Accuracy Paradox, relying on metrics like Precision and Recall, and utilizing techniques like SMOTE or Class Weights, you ensure your models are actually solving the problem they were built for, rather than just taking the mathematically easiest way out.
FAQ
Q: Can I use SMOTE before doing a Train-Test split?
A: Absolutely never. This is a classic rookie mistake called "data leakage." If you apply SMOTE to the entire dataset, synthetic data generated from the test set will bleed into the training set. Your model will perform incredibly well during testing, but will fail in production. Always split your data first, and only apply SMOTE to the training set.
Q: Is it possible for a dataset to be too imbalanced for machine learning?
A: Yes. If your minority class has only 5 or 10 examples in a dataset of a million, standard ML algorithms will struggle regardless of resampling. In such extreme anomaly detection scenarios, unsupervised learning techniques (like Isolation Forests or One-Class SVMs) are usually more effective than standard classification models.
Q: Does changing the decision threshold help with imbalance?
A: Yes! By default, algorithms classify an output as "Positive" if the probability is > 0.5. In imbalanced scenarios (like cancer detection), you might want to lower that threshold to 0.2 or 0.3 to increase Recall, ensuring the model flags potential cases even if it isn't completely certain.
Var denne artikkelen nyttig?
Del:
Var denne artikkelen nyttig?
Del:
Relaterte kurs
Se alle kursMiddelsnivå
Introduction to Machine Learning with Python
Machine learning is now used everywhere. Want to learn it yourself? This course is an introduction to the world of Machine learning for you to learn basic concepts, work with Scikit-learn – the most popular library for ML and build your first Machine Learning project. This course is intended for students with a basic knowledge of Python, Pandas, and Numpy.
Nybegynner
Data Preprocessing and Feature Engineering with Python
Learn practical techniques to clean, transform, and engineer data for machine learning using Python. This course covers essential preprocessing steps, feature creation, and hands-on challenges to prepare data for modeling.
Synthetic Data and the Future of AI Training
How to Train Models When Real Data Is Scarce or Sensitive
by Arsenii Drobotenko
Data Scientist, Ml Engineer
Feb, 2026・5 min read

Sequential Backward and Forward Selection
Sequential Backward and Forward Selection
by Andrii Chornyi
Data Scientist, ML Engineer
Jan, 2024・15 min read

Target Encoding Implementation
Target Encoding Implementation
by Andrii Chornyi
Data Scientist, ML Engineer
Jan, 2024・7 min read

Innholdet i denne artikkelen
